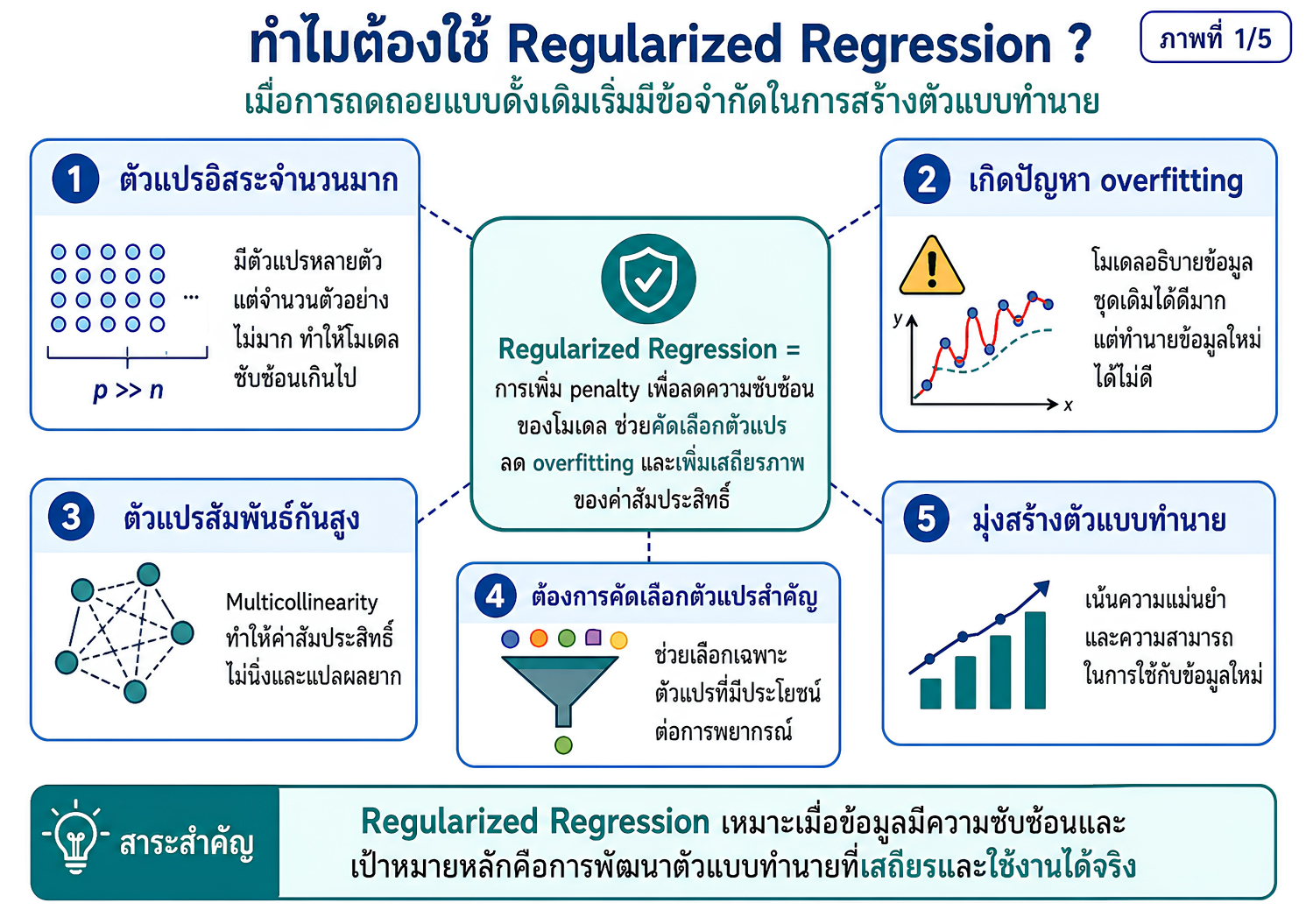
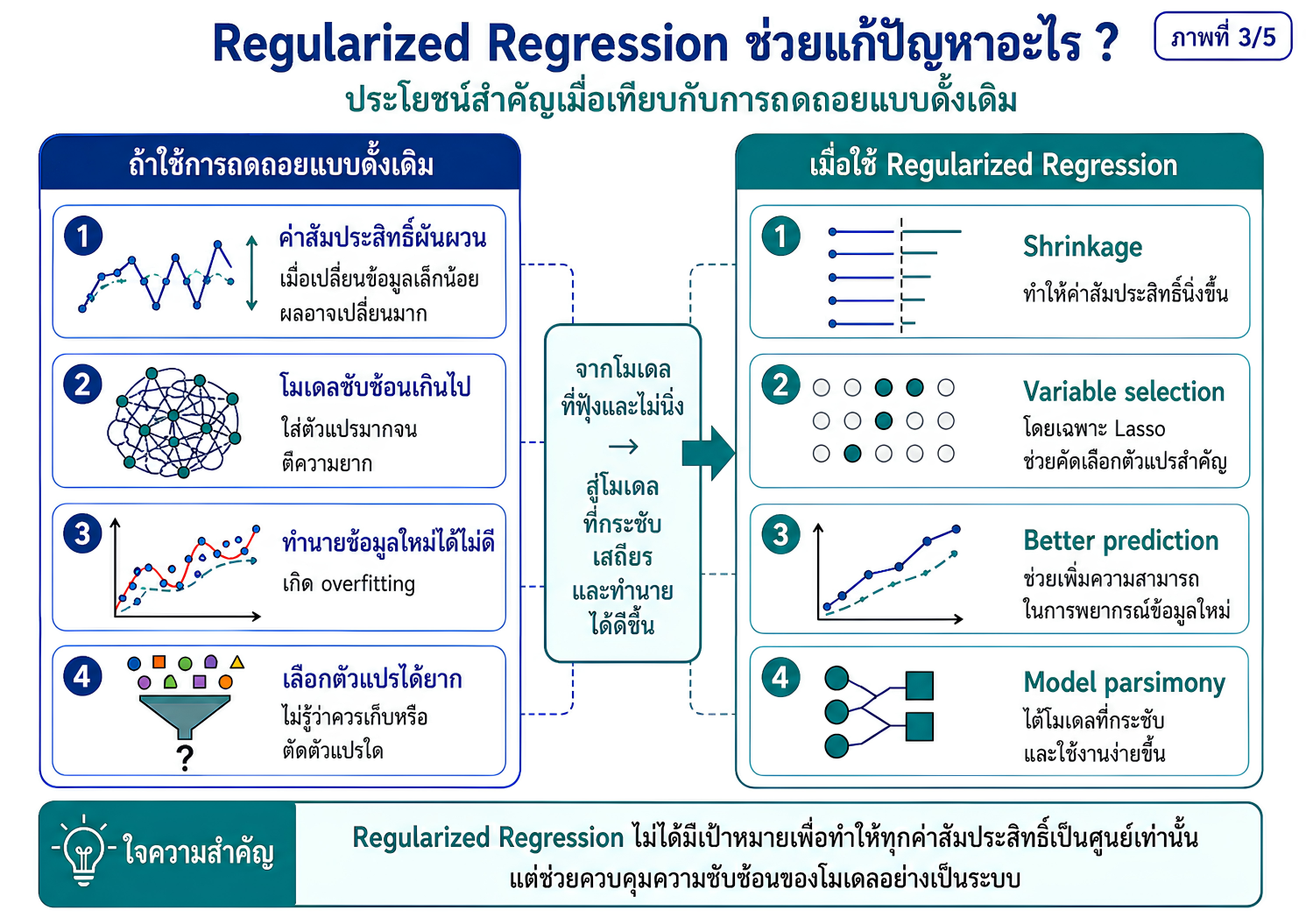
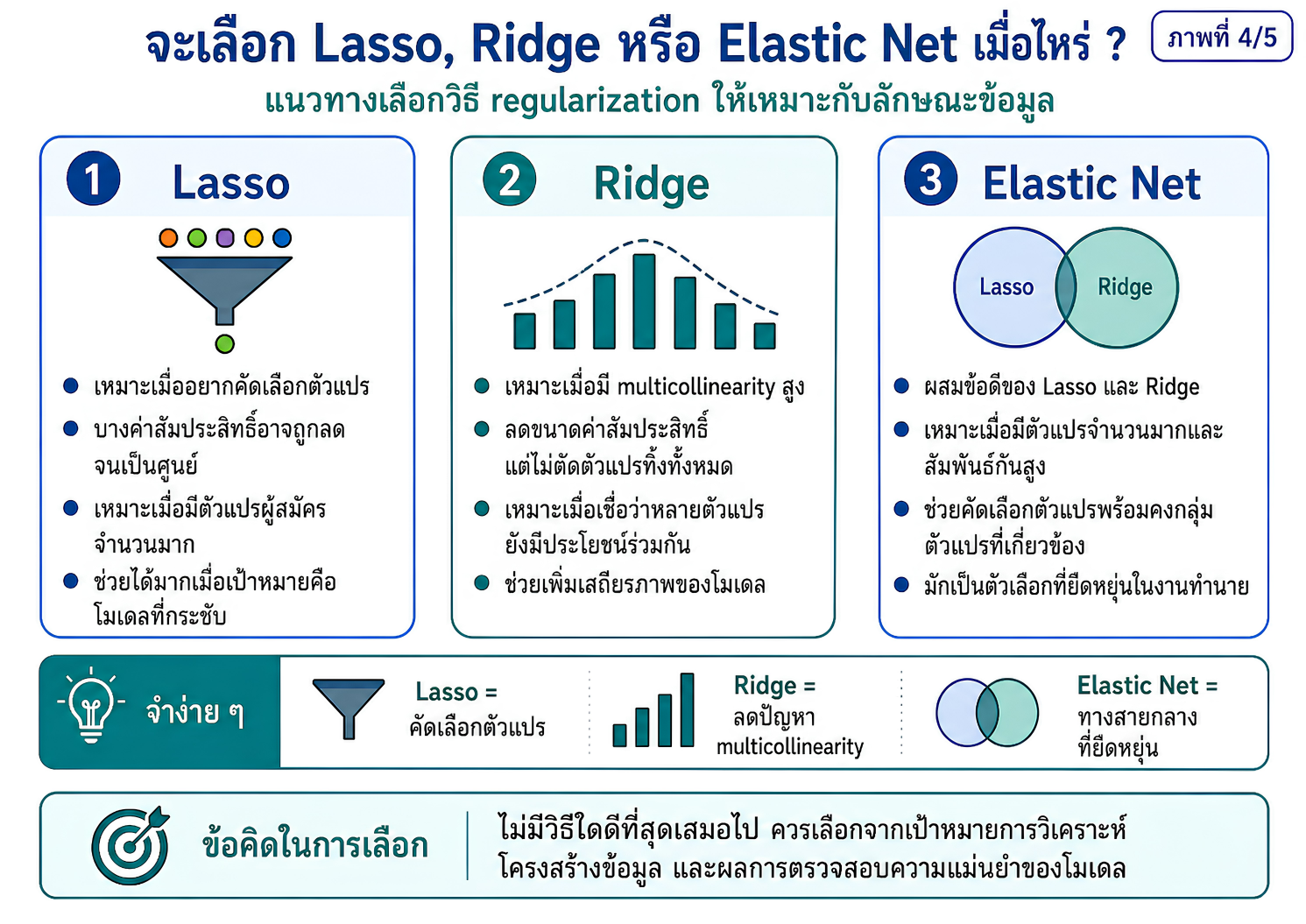
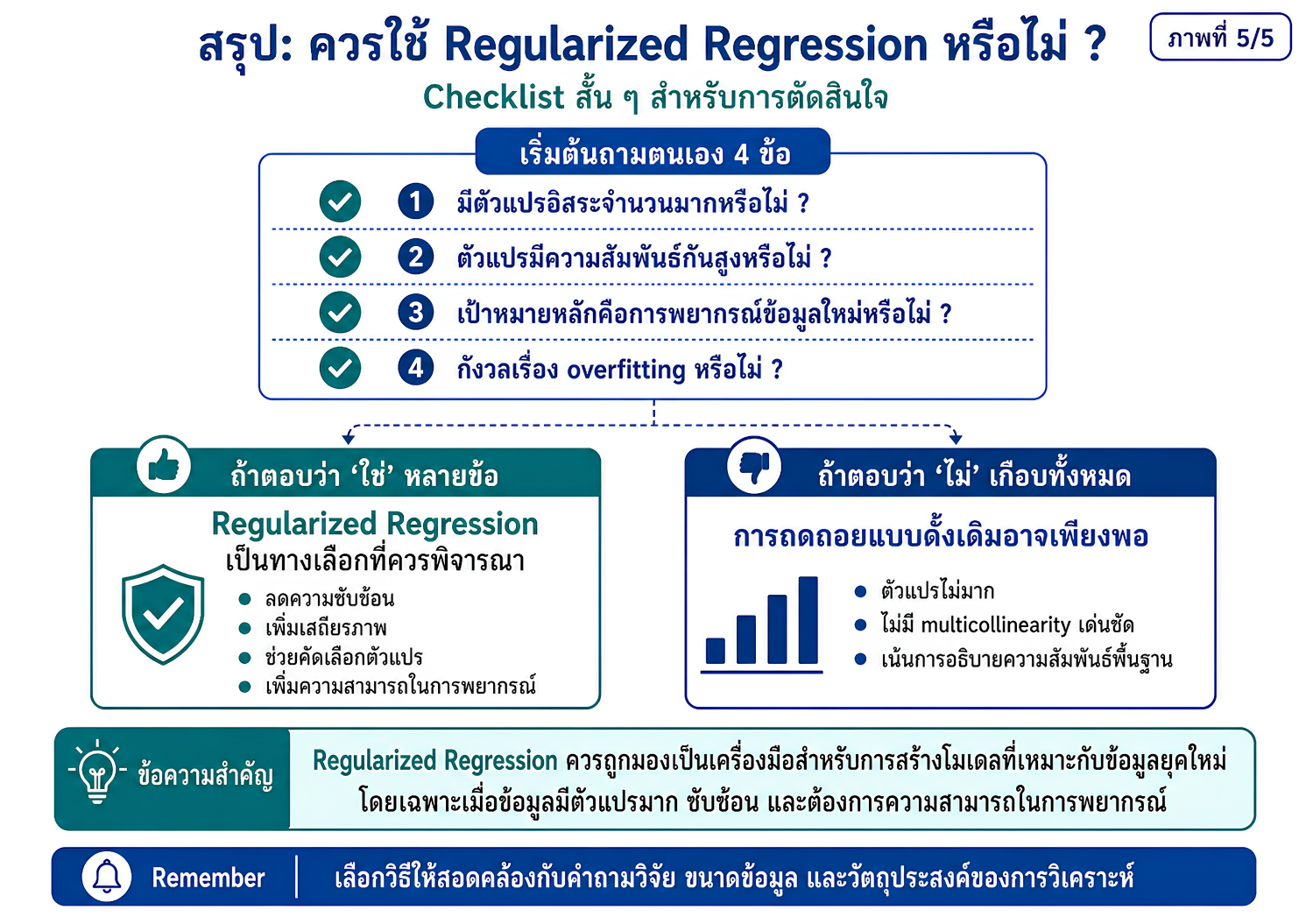
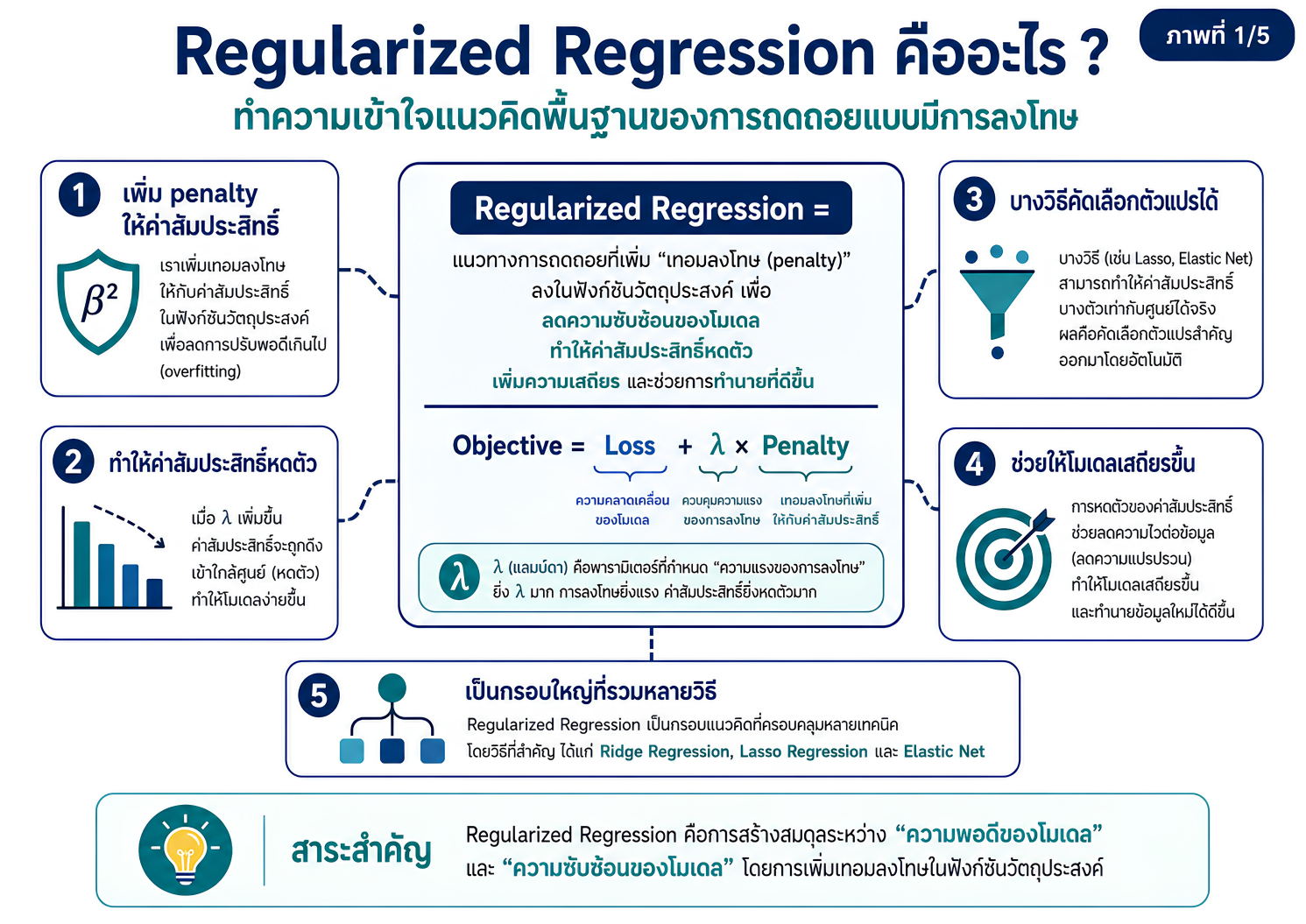
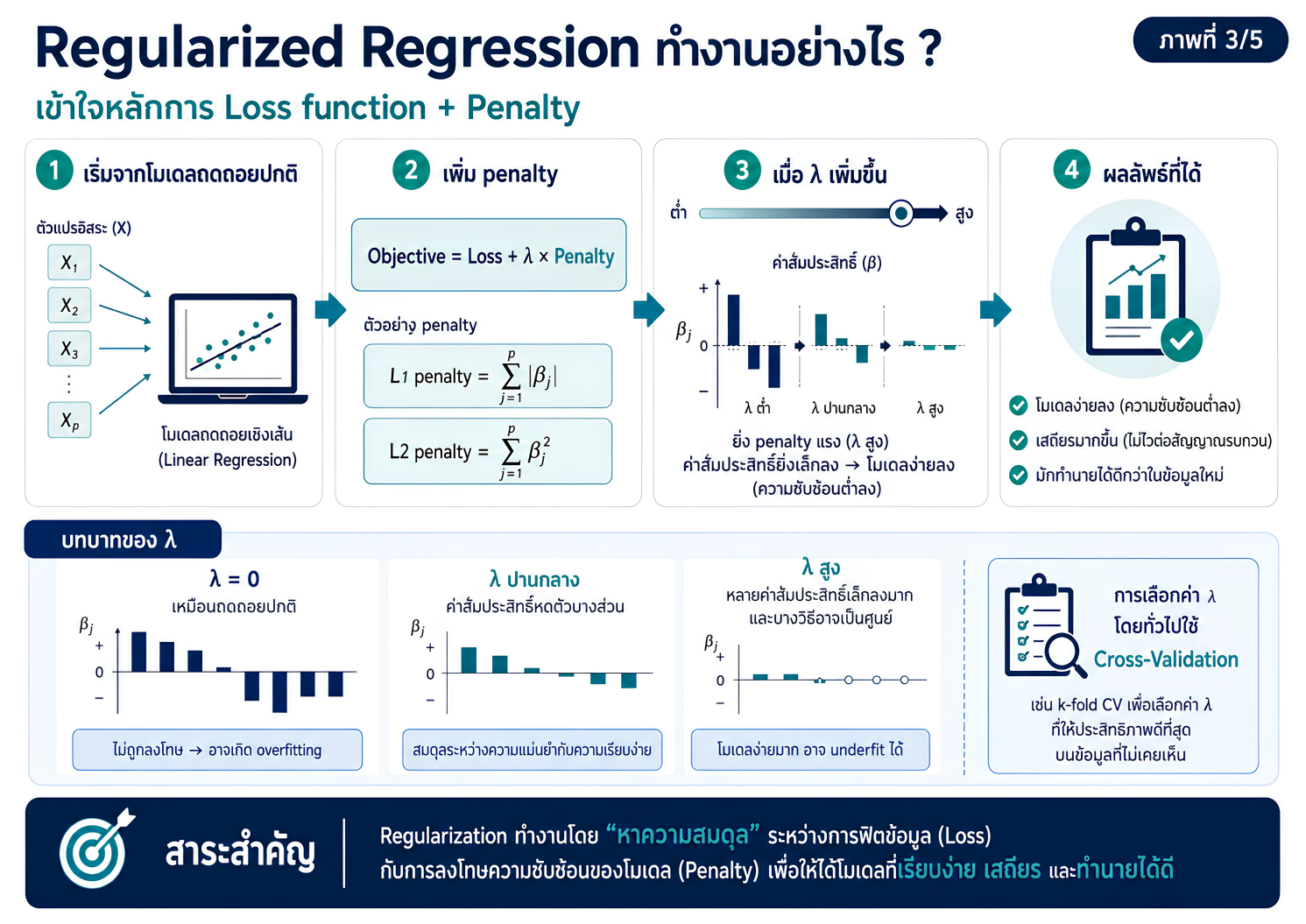
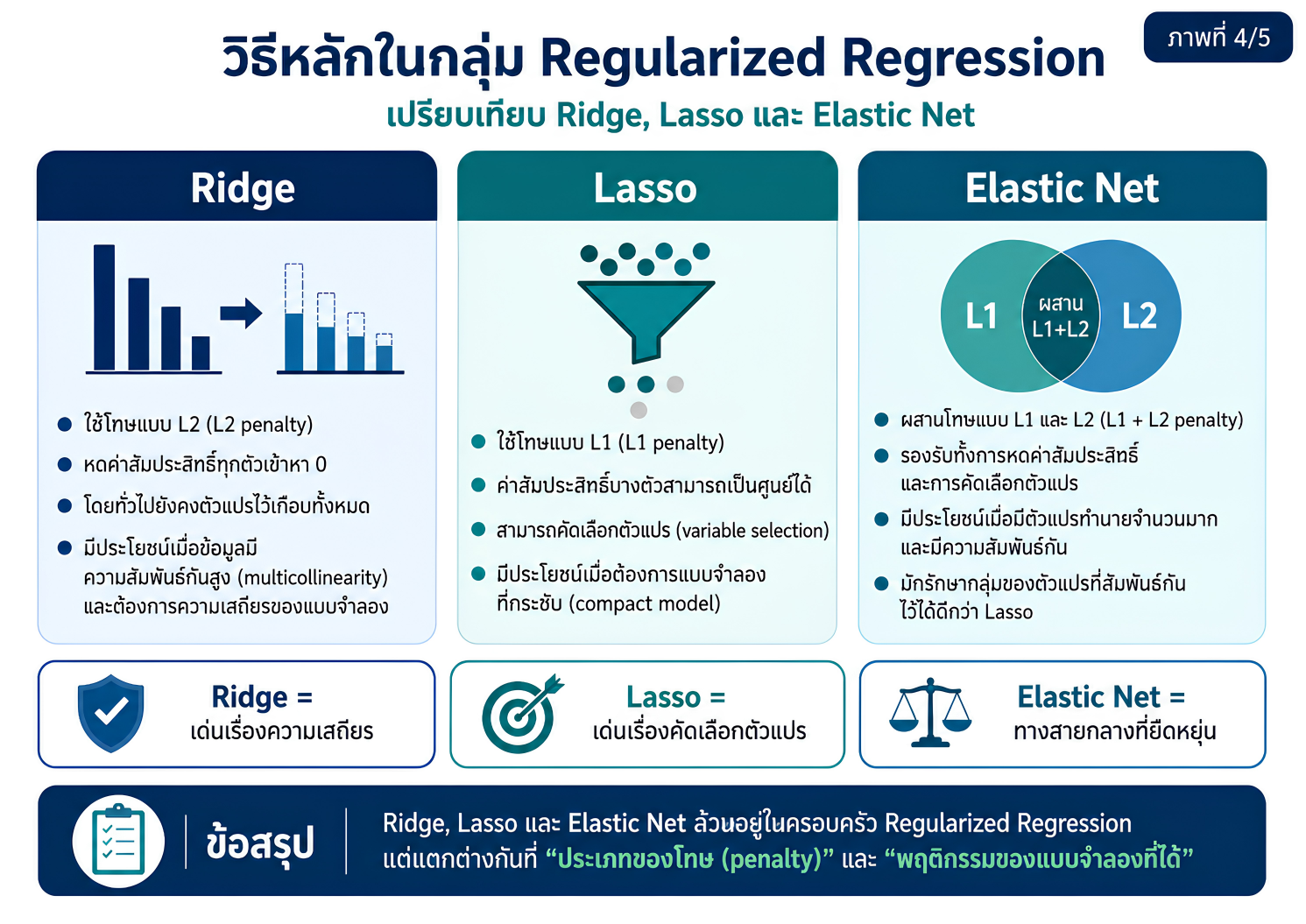
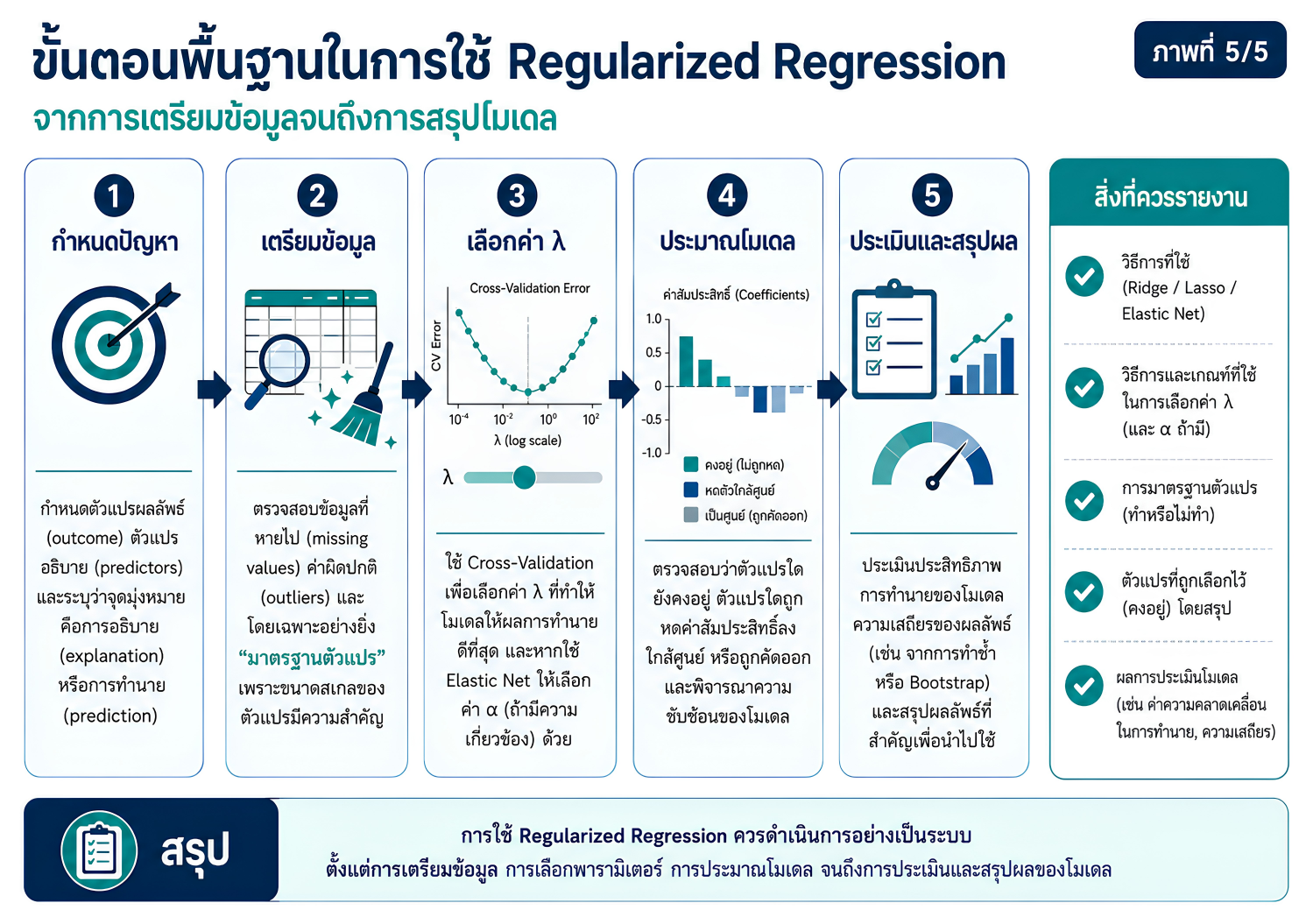
แหล่งเรียนรู้เพื่อปูพื้นแนวคิดเกี่ยวกับการพัฒนาตัวแบบทำนายในงานวิจัยทางวิทยาศาสตร์สุขภาพ โดยเชื่อมโยงจากการวิเคราะห์ถดถอยแบบดั้งเดิม ไปสู่ regularized regression และ machine learning อย่างเป็นระบบ
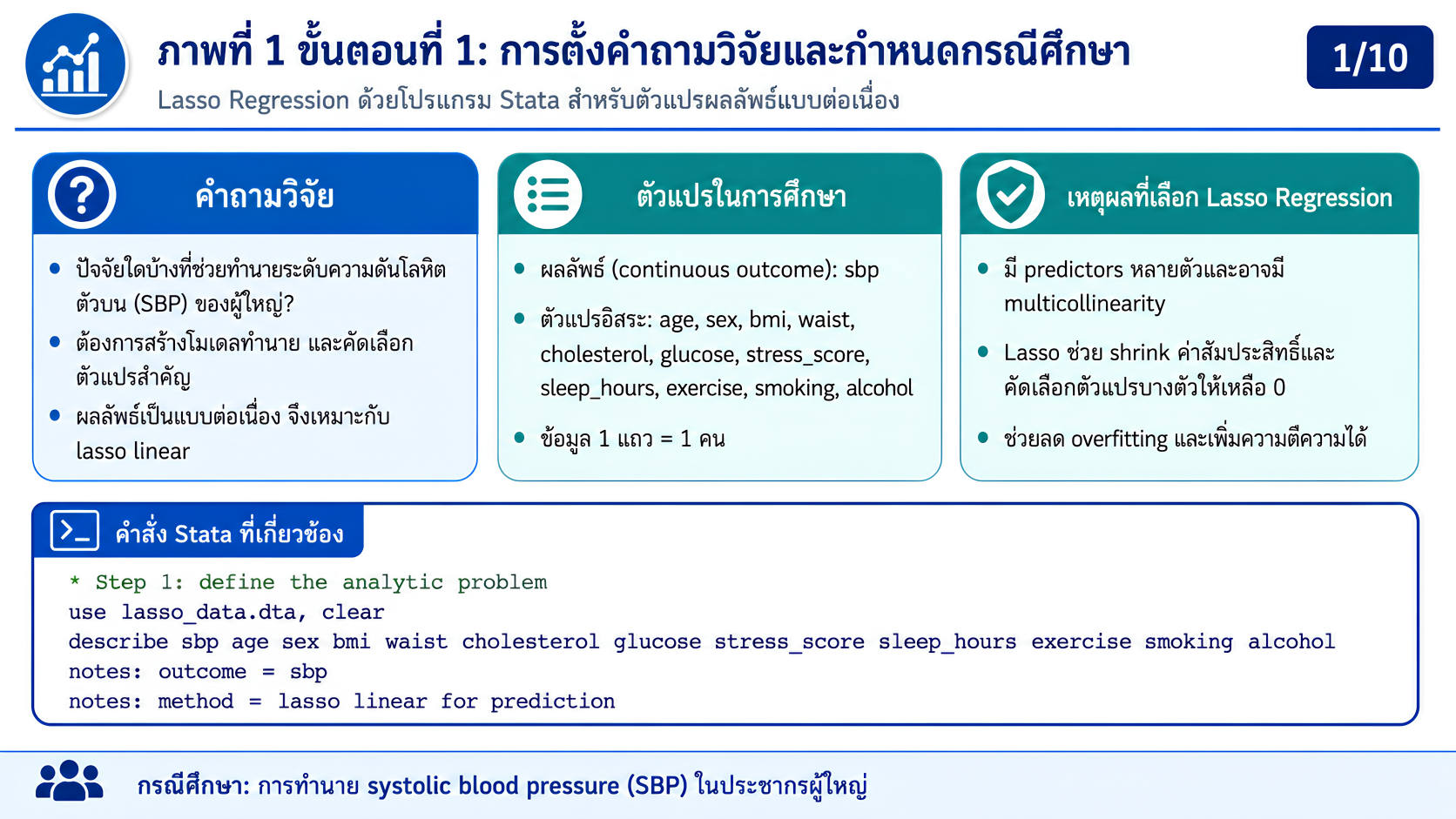
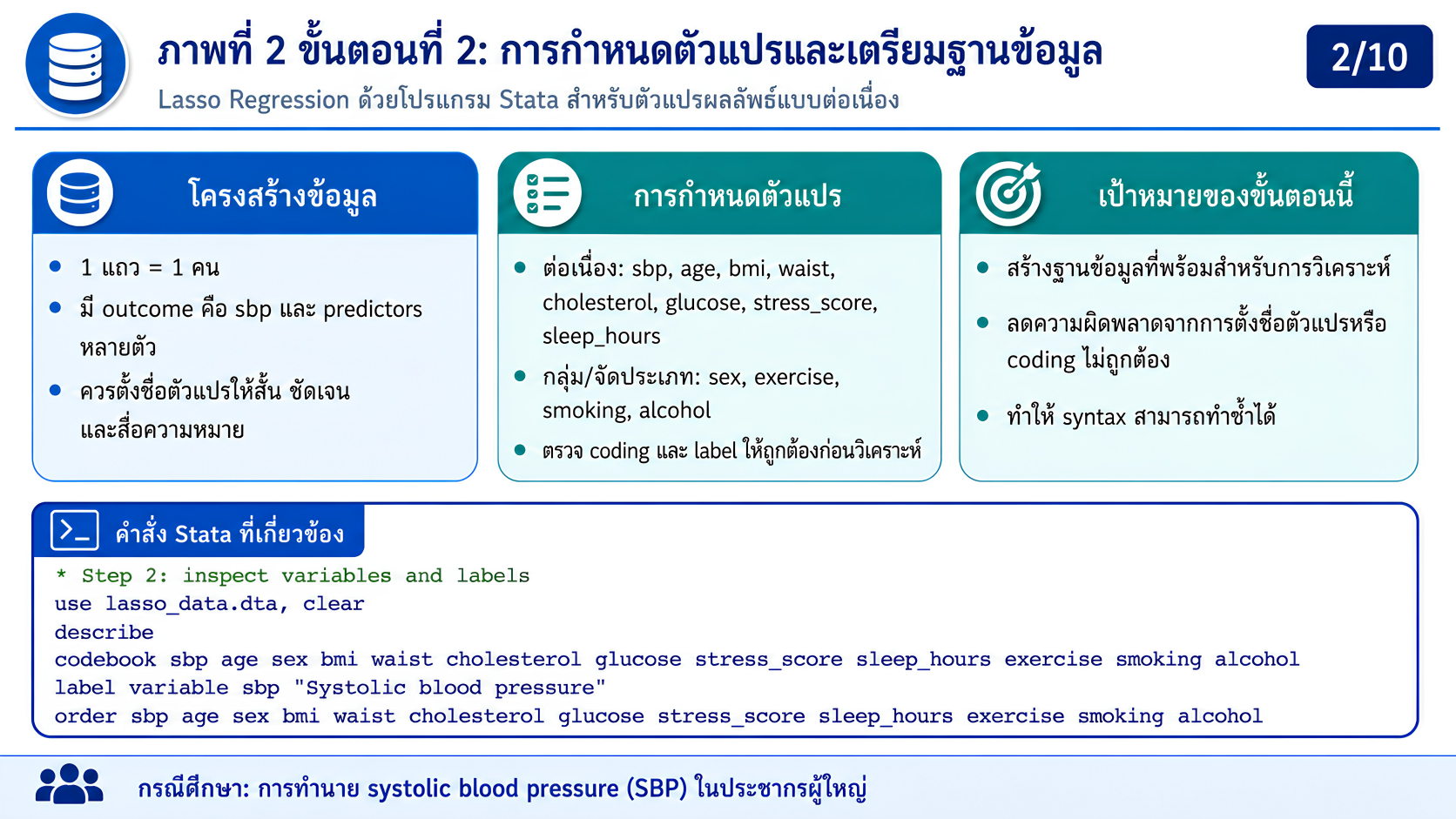
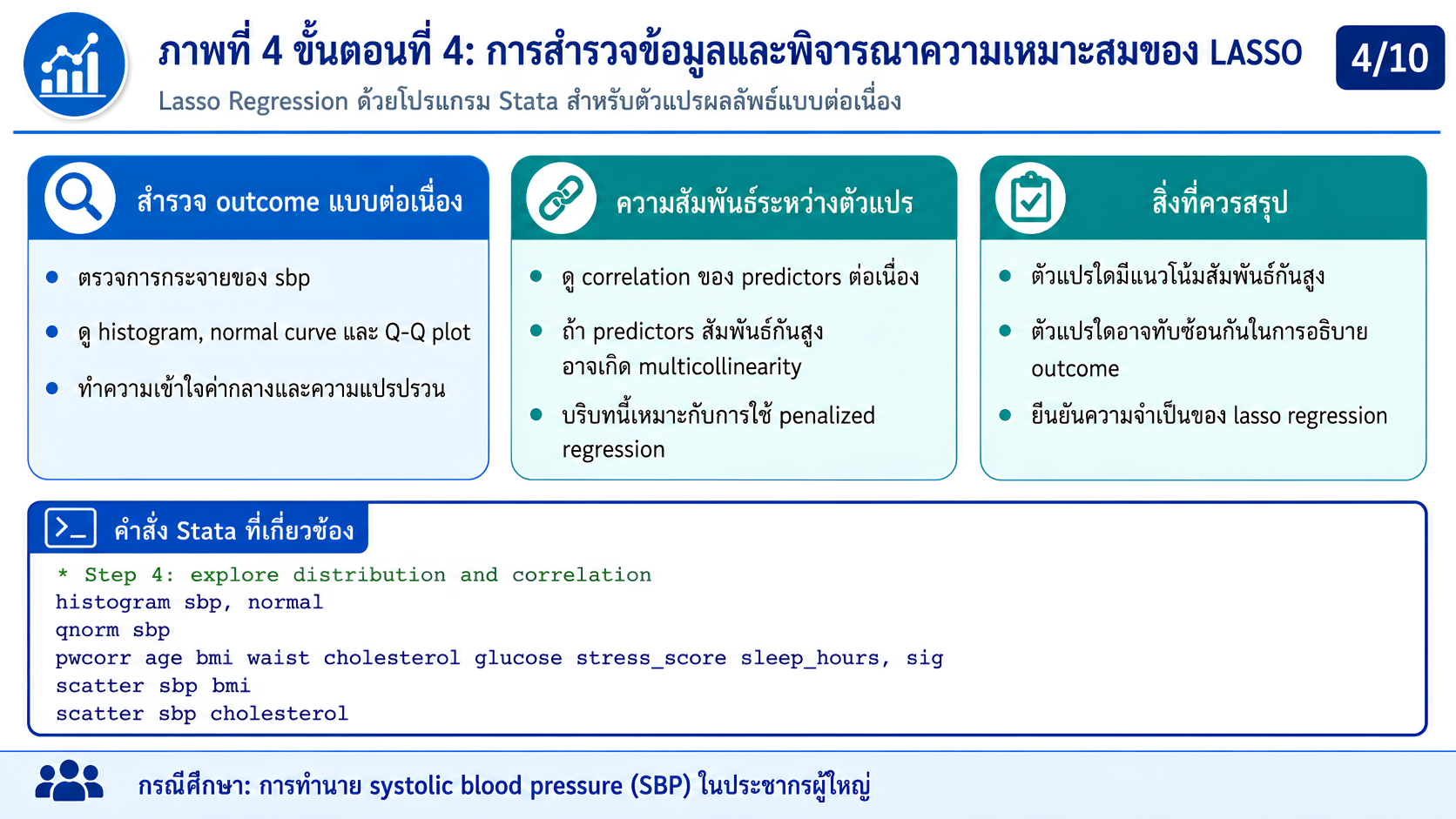
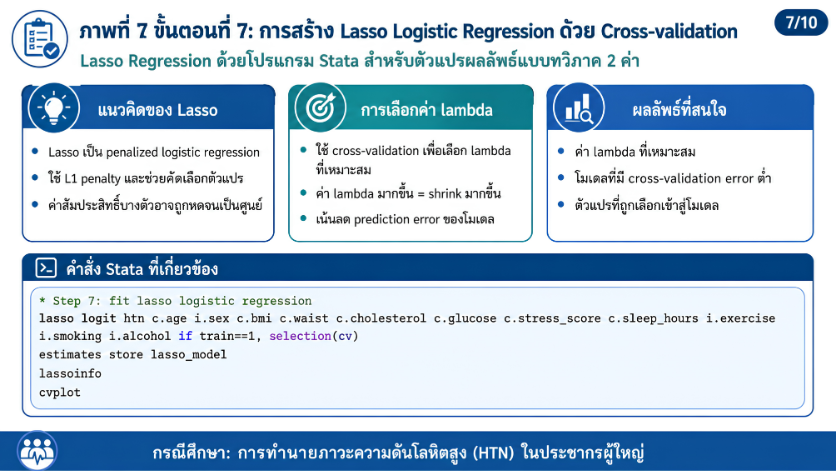
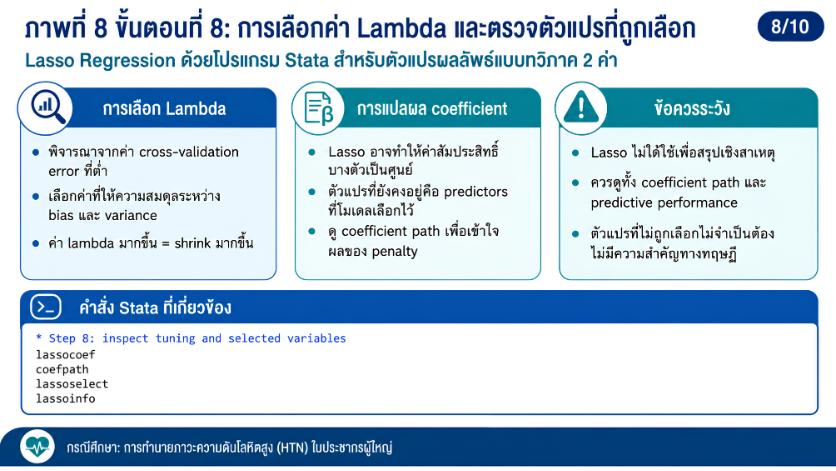
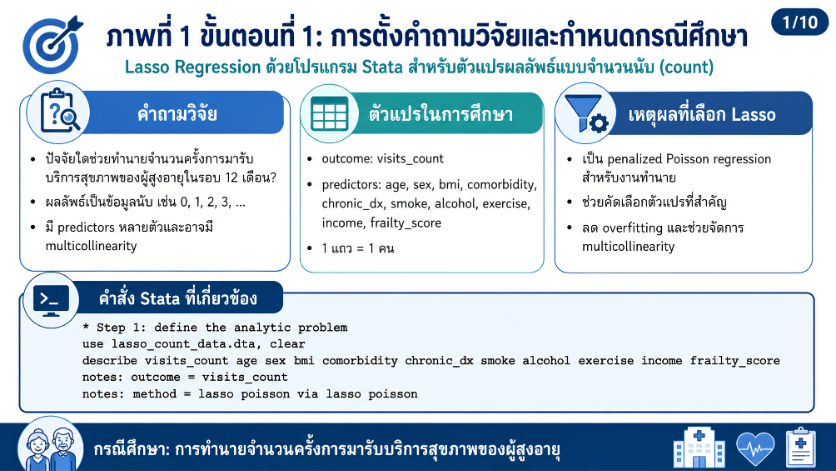
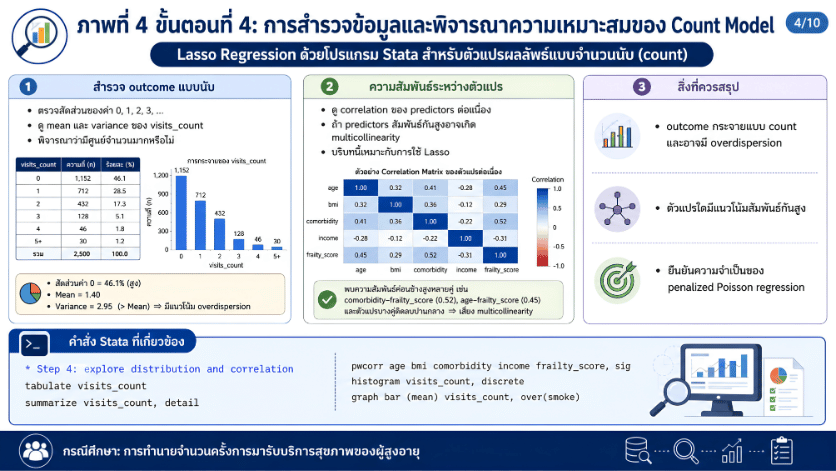
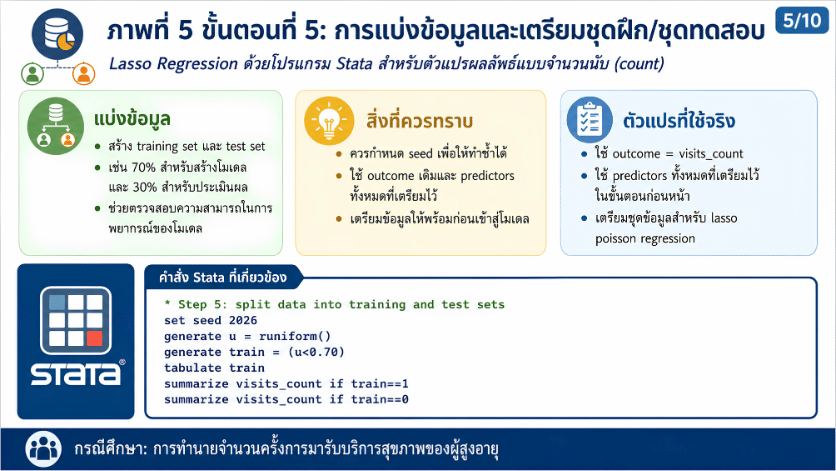
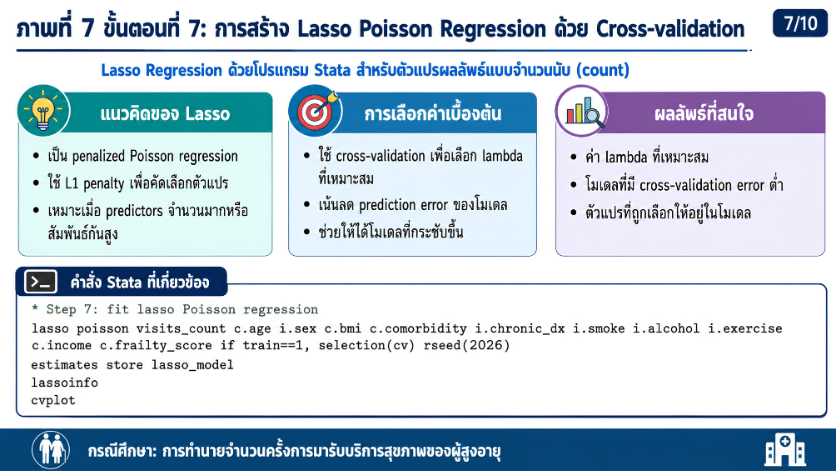
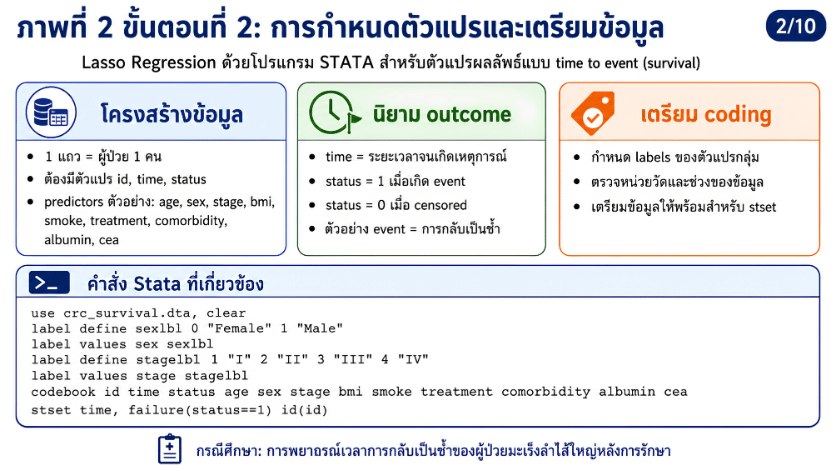
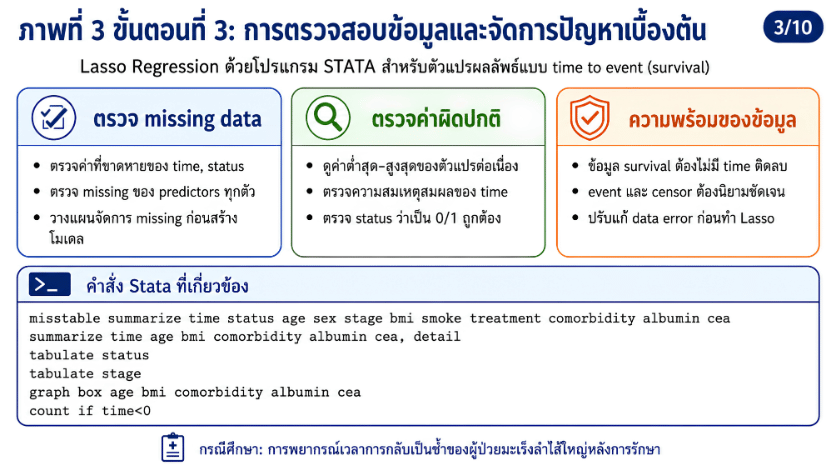
>>> ขั้นตอนการวิเคราะห์ Lasso Regression ด้วยโปรแกรม STATA
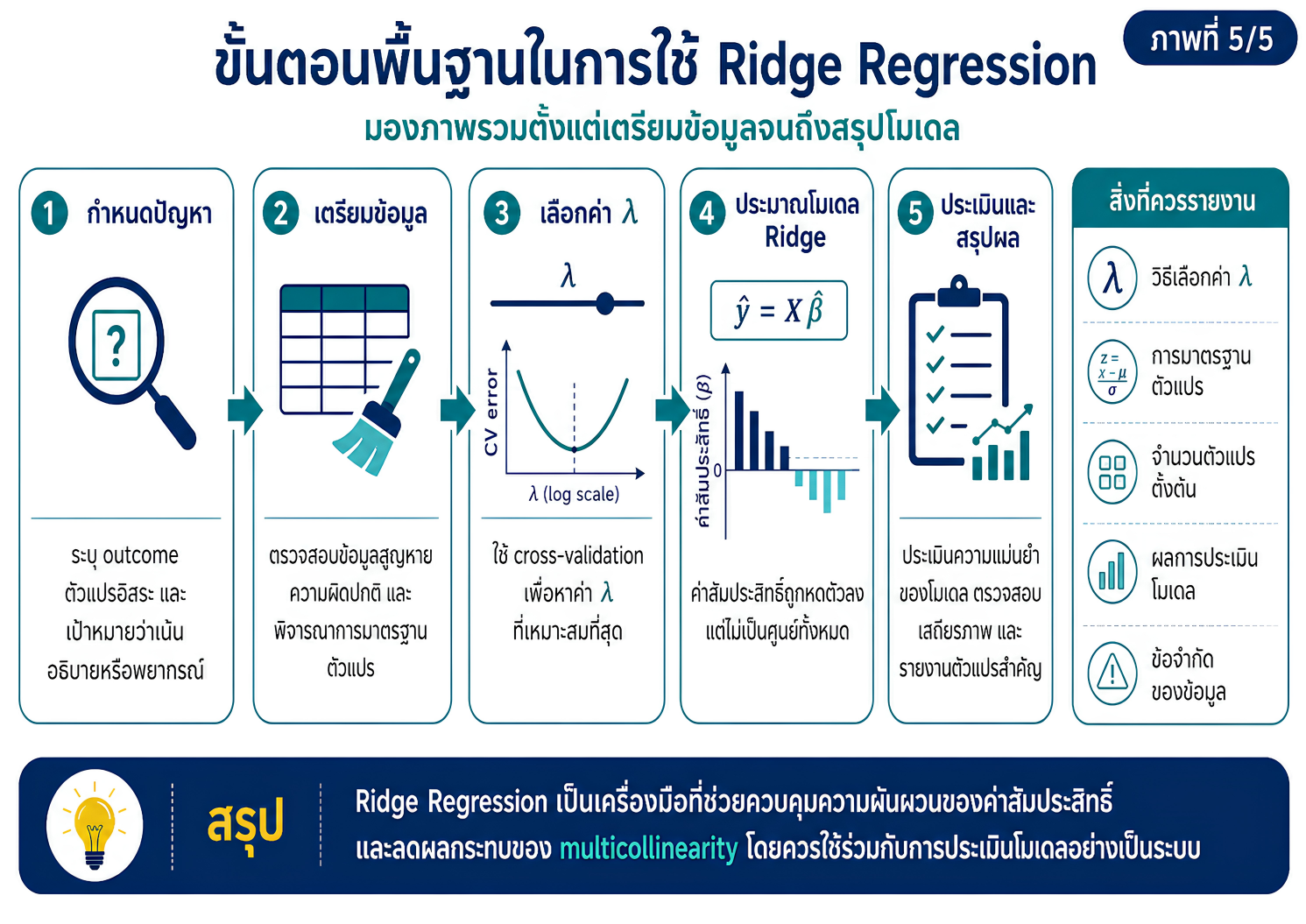
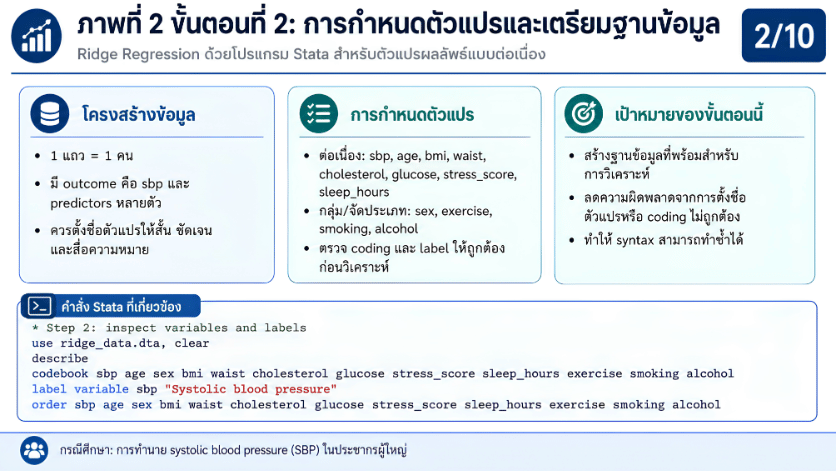
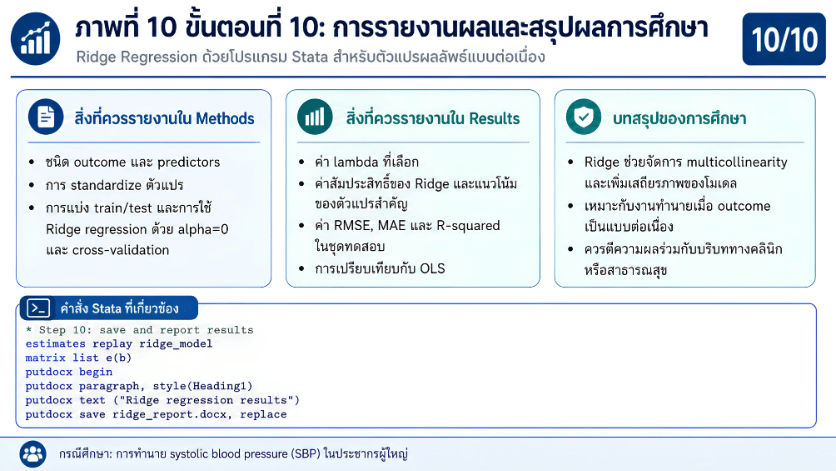
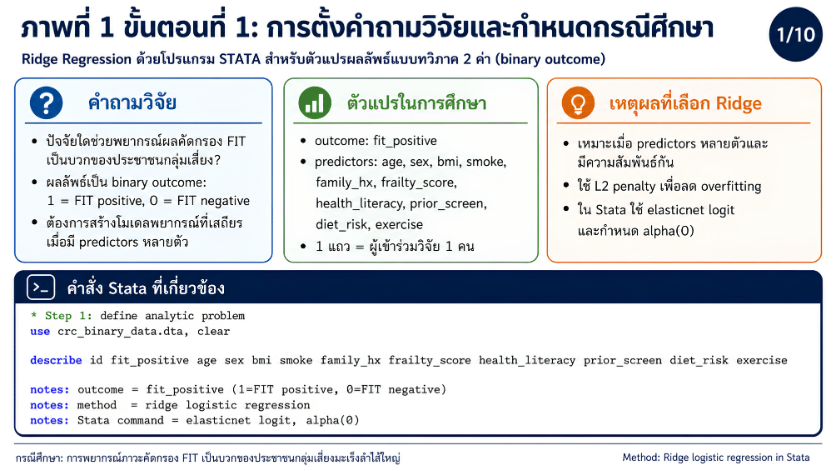
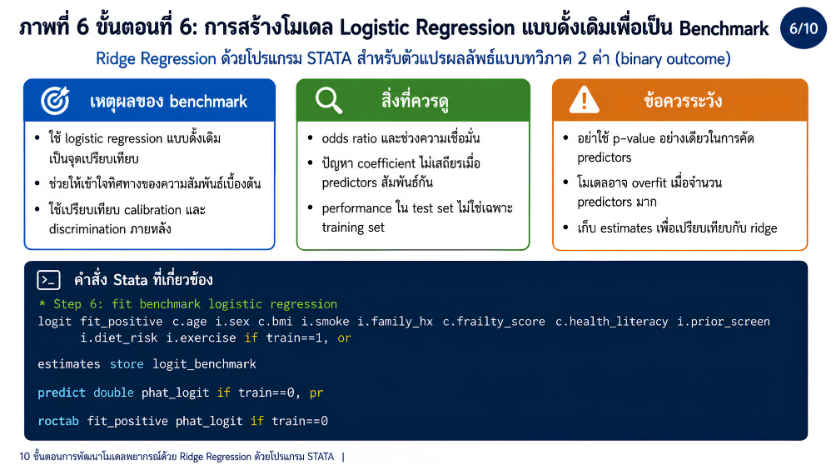
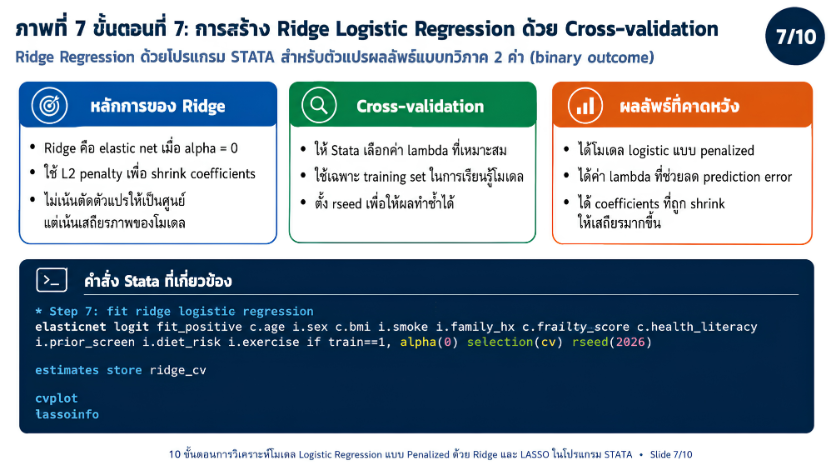
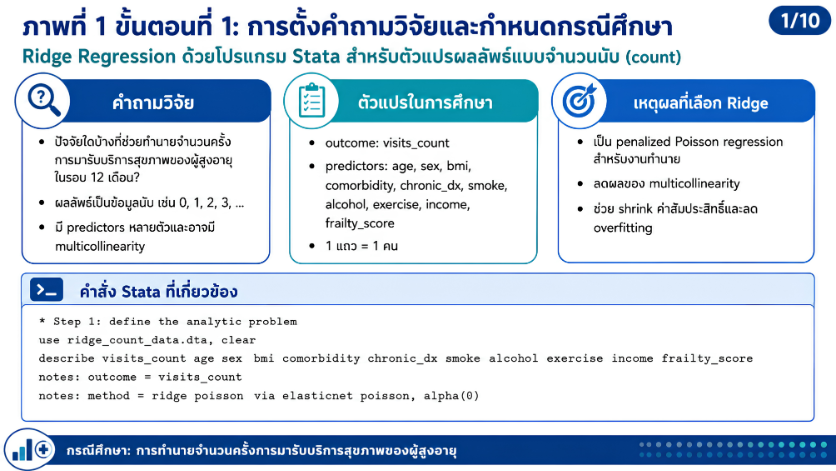
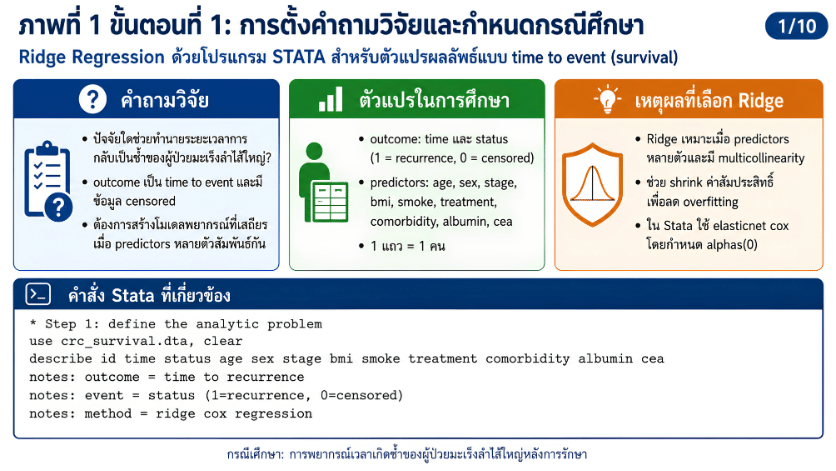
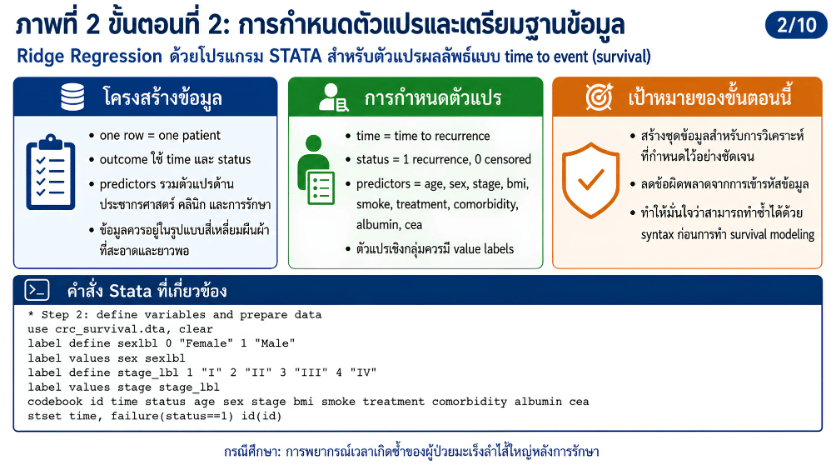
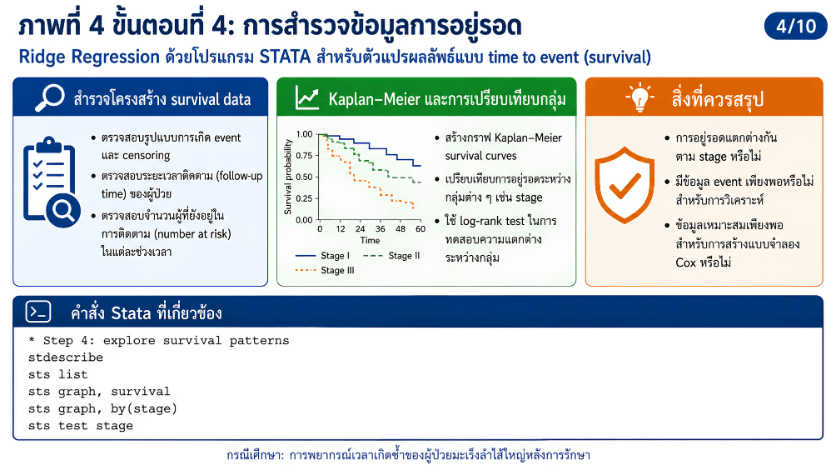
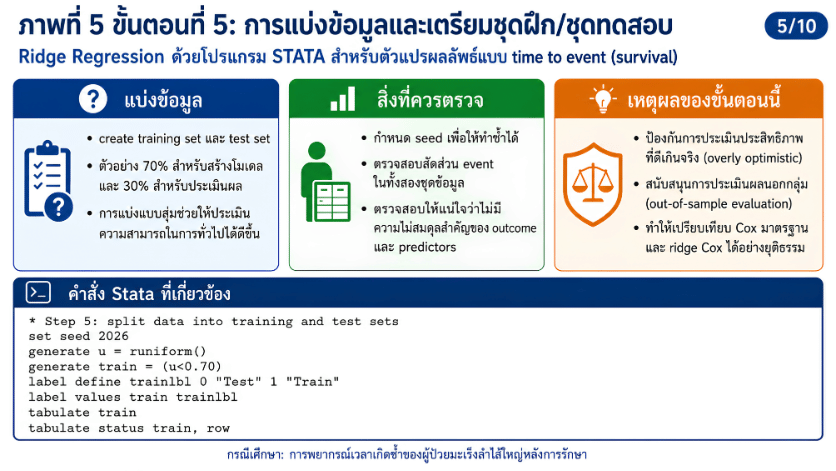
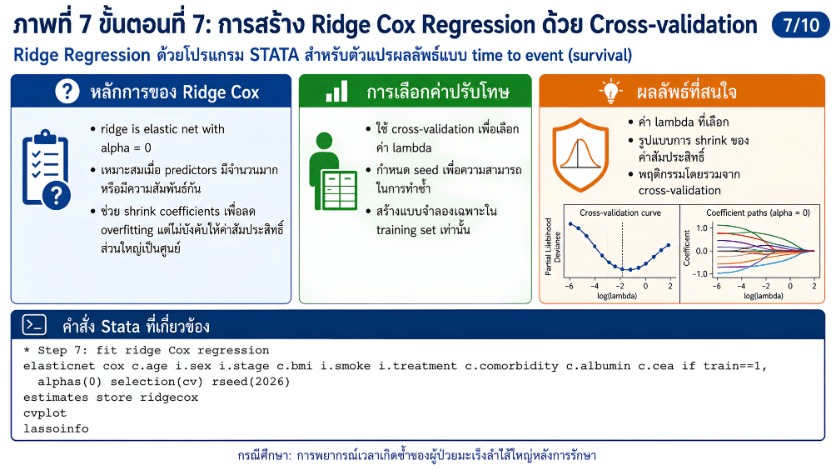
>>> ขั้นตอนการวิเคราะห์ Ridge Regression ด้วยโปรแกรม STATA
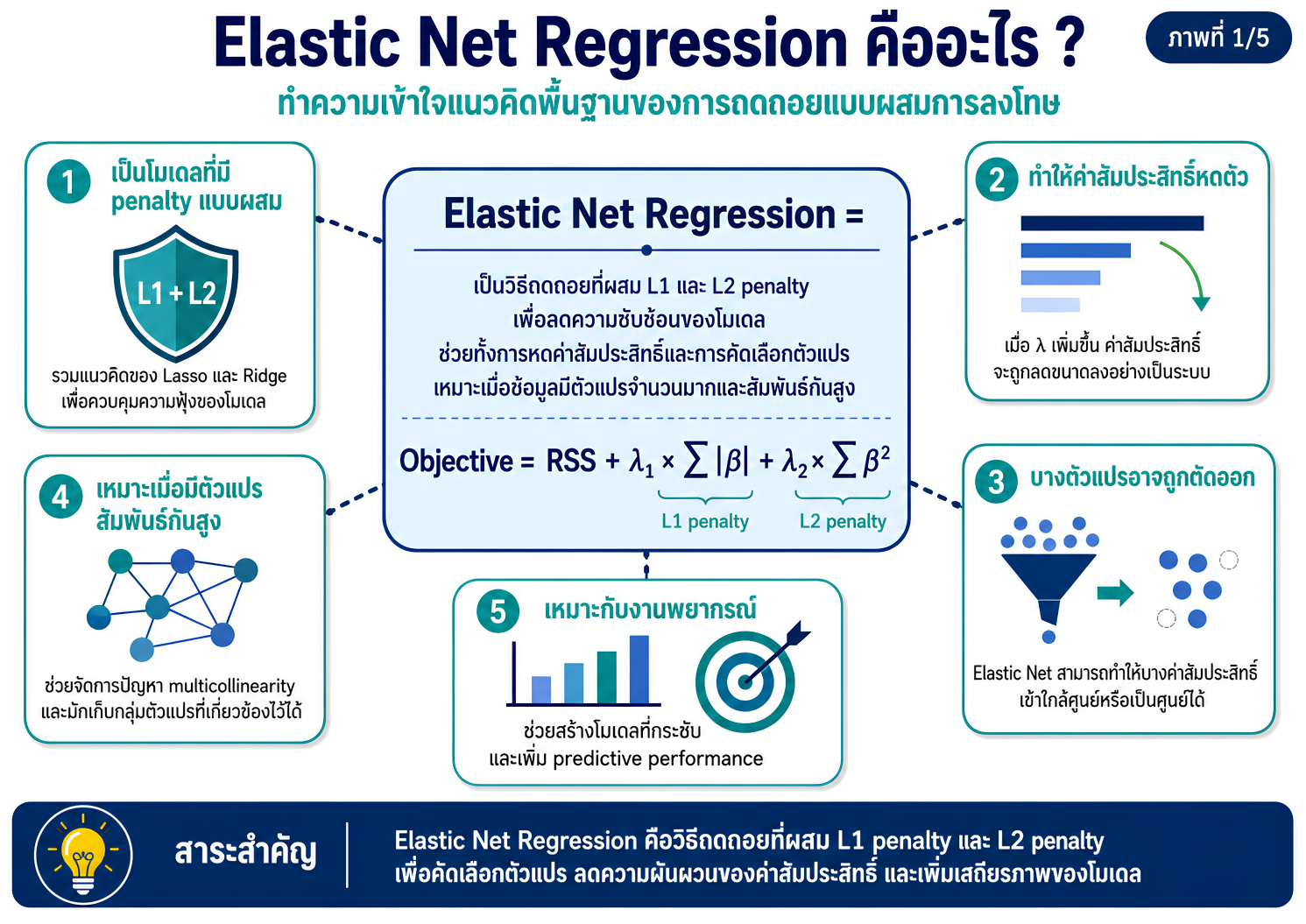
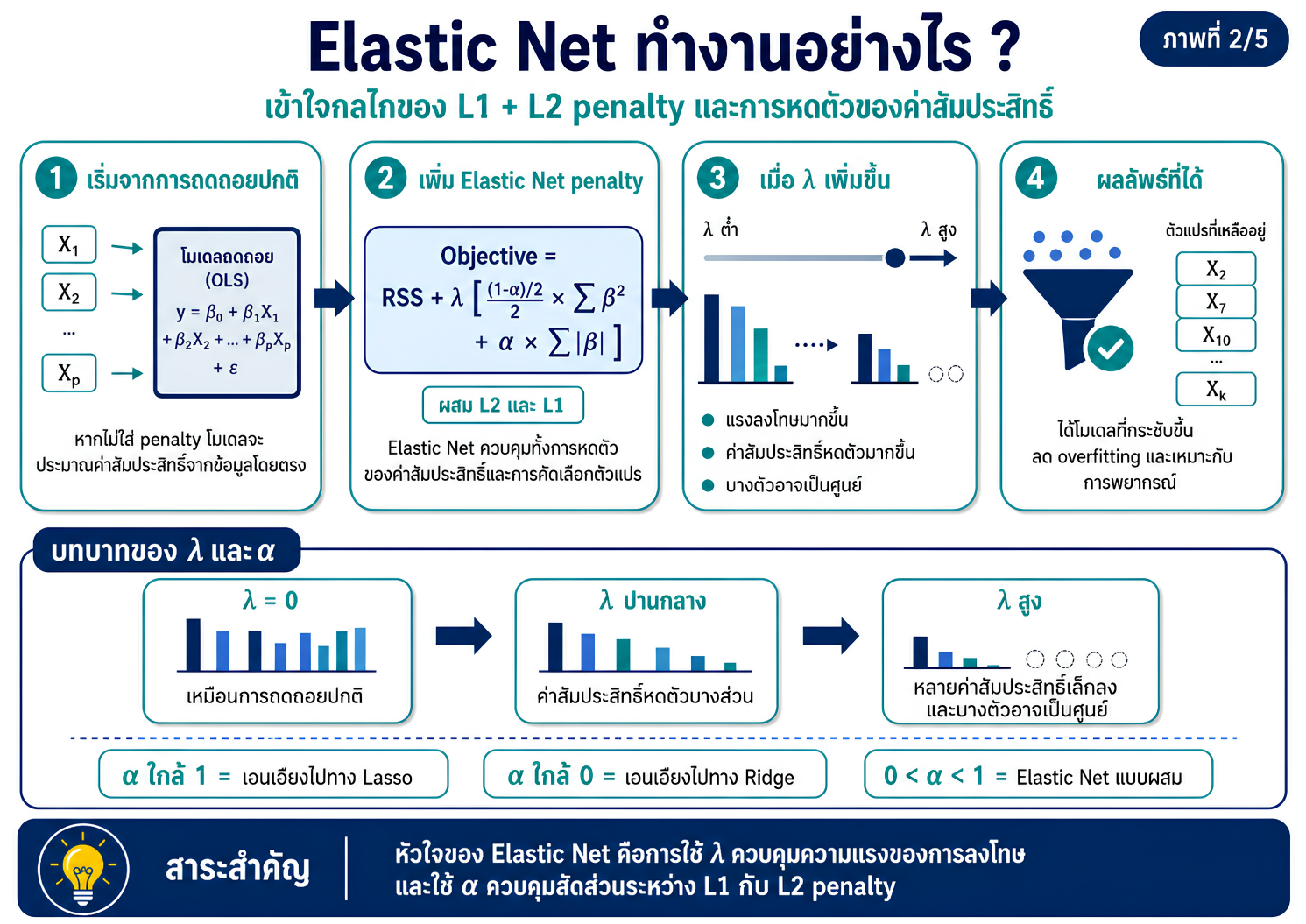
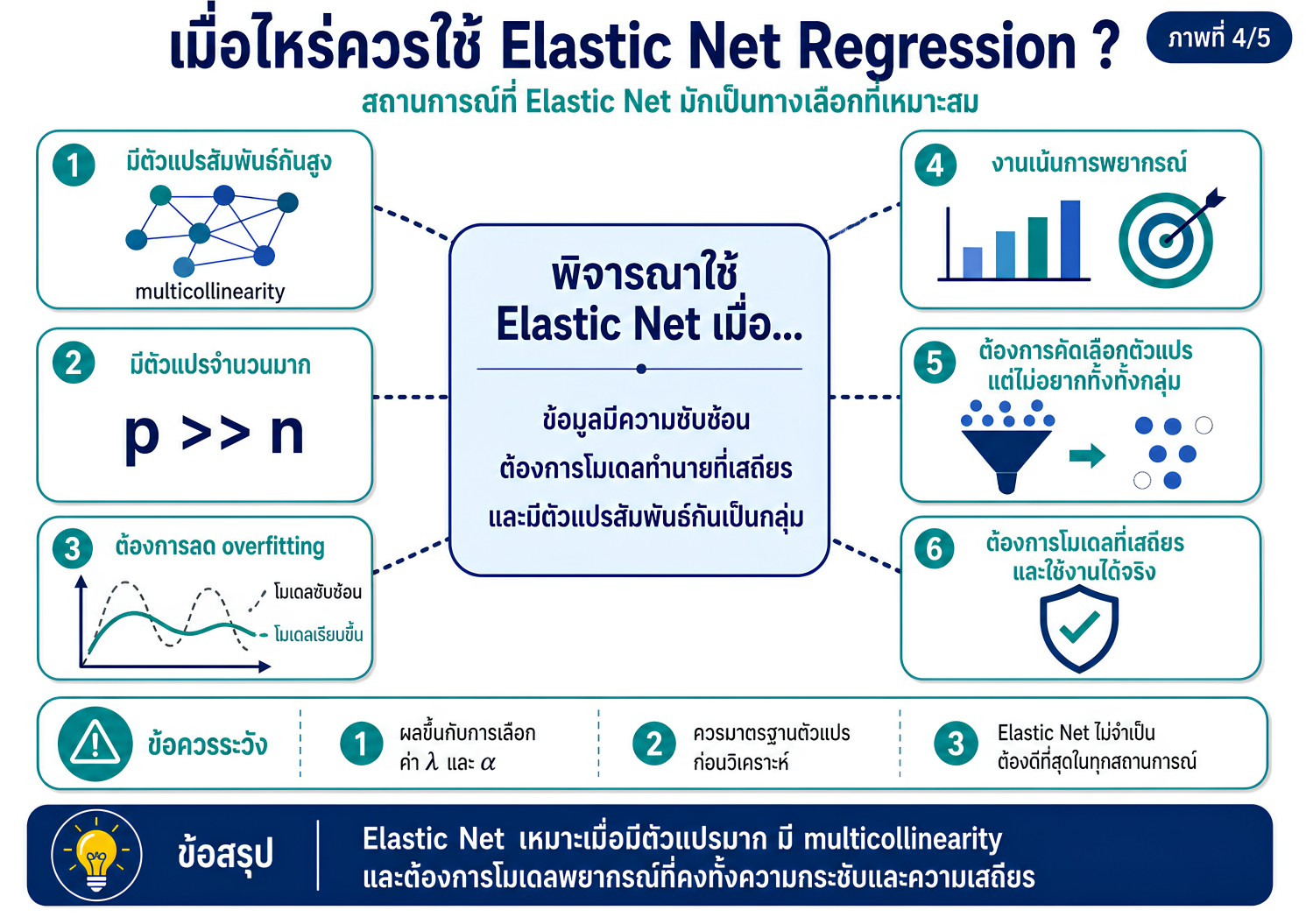
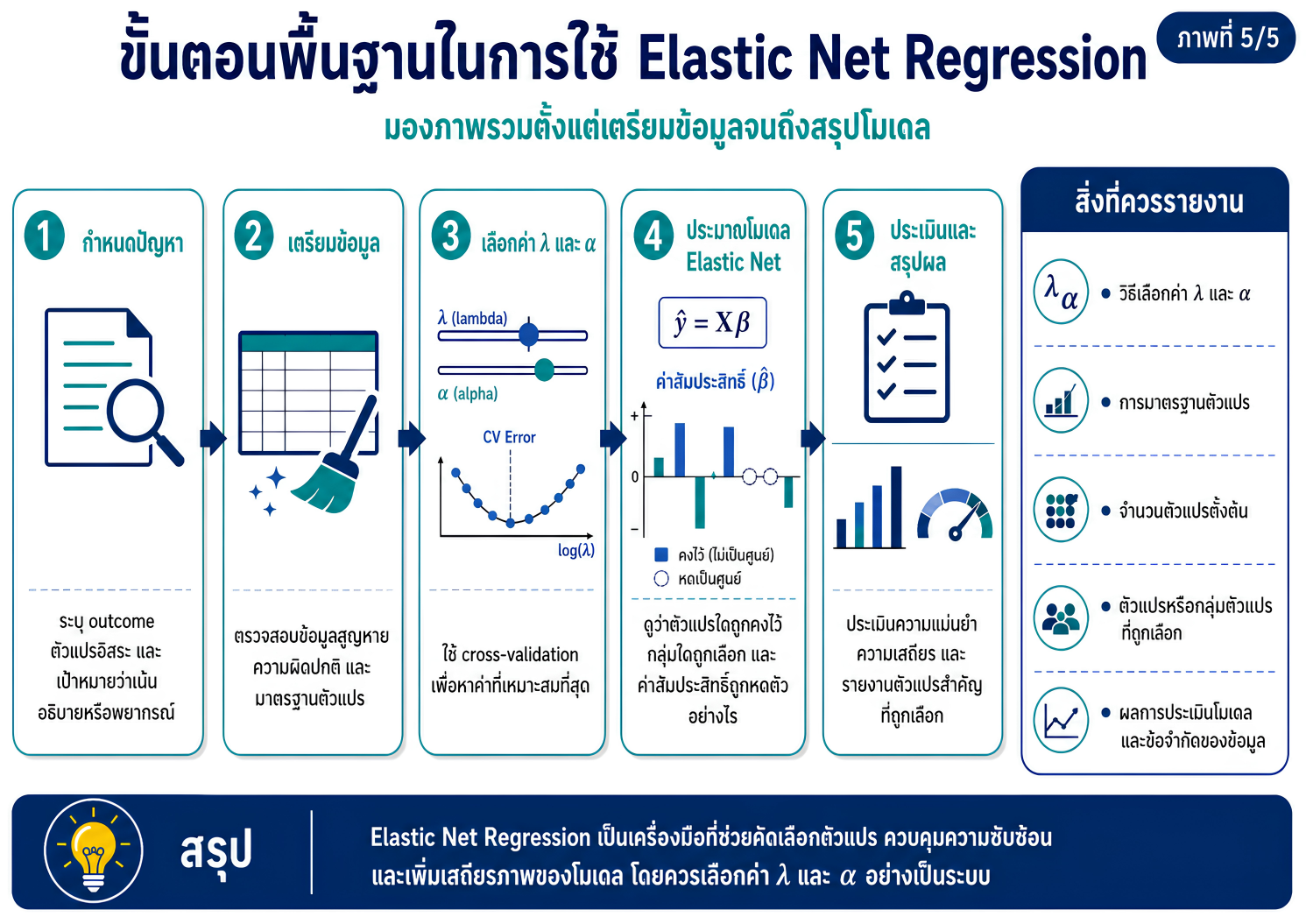
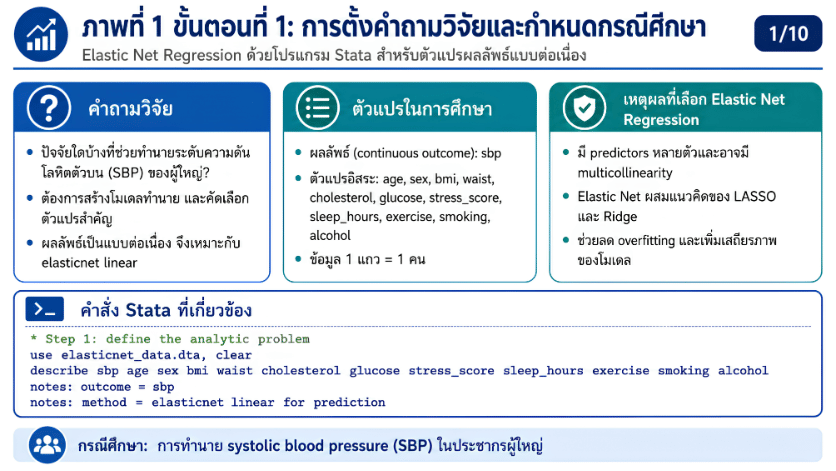
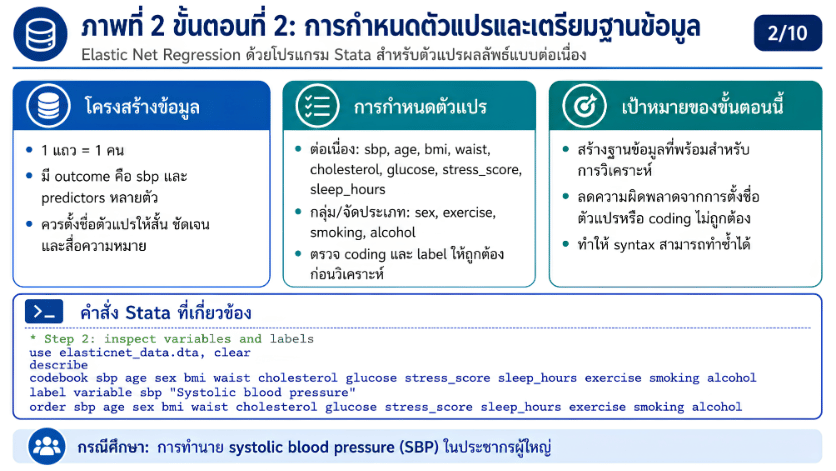
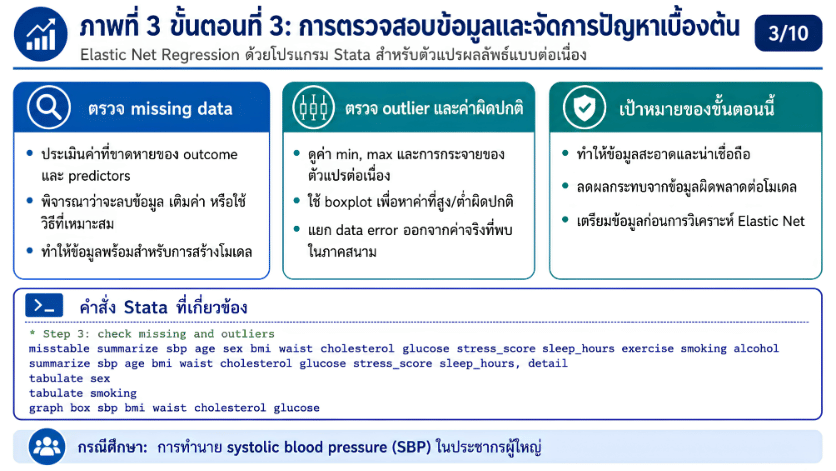
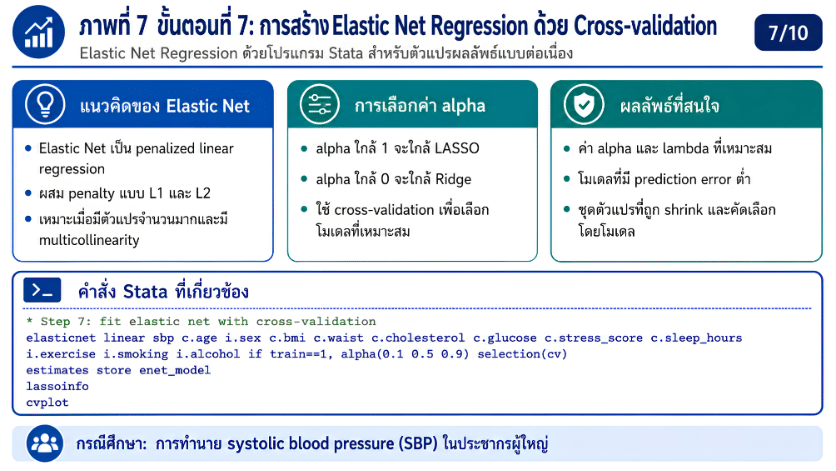
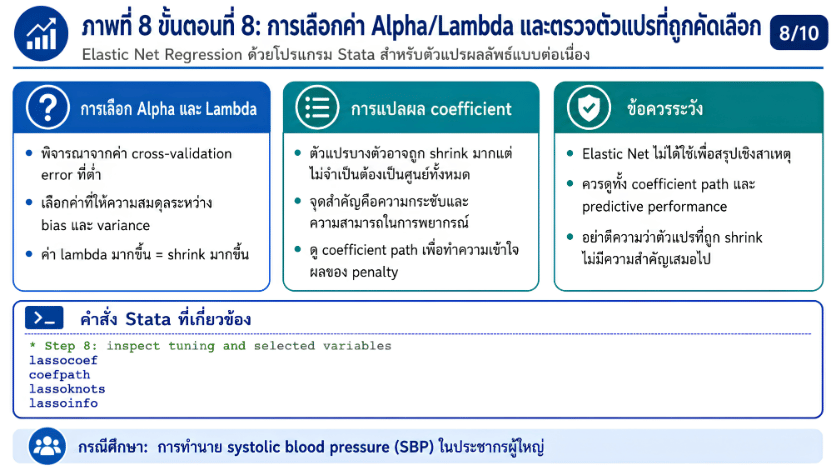
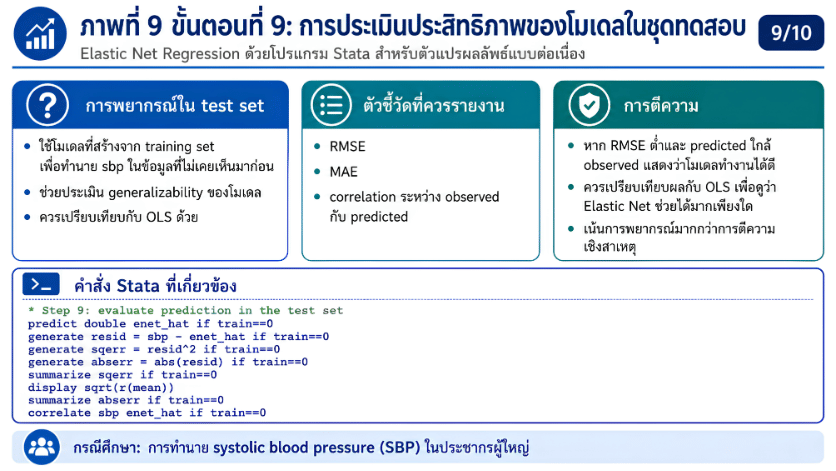
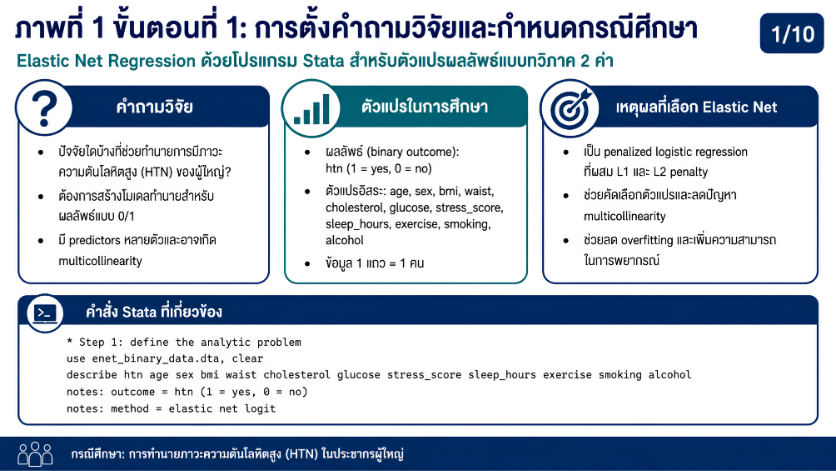
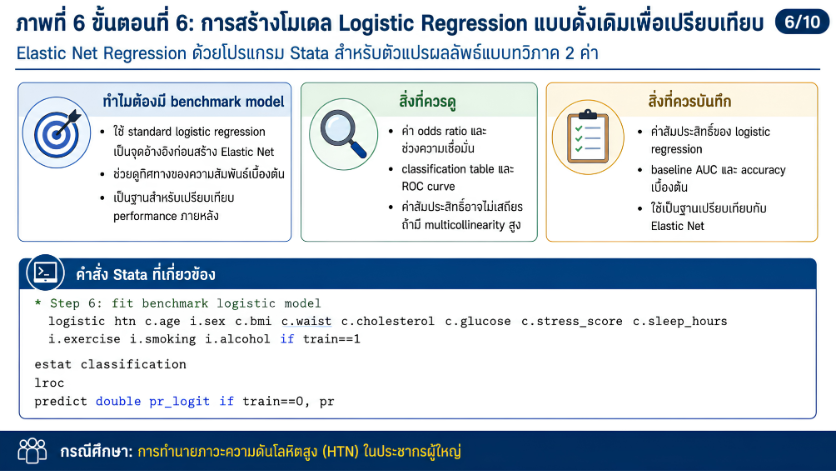
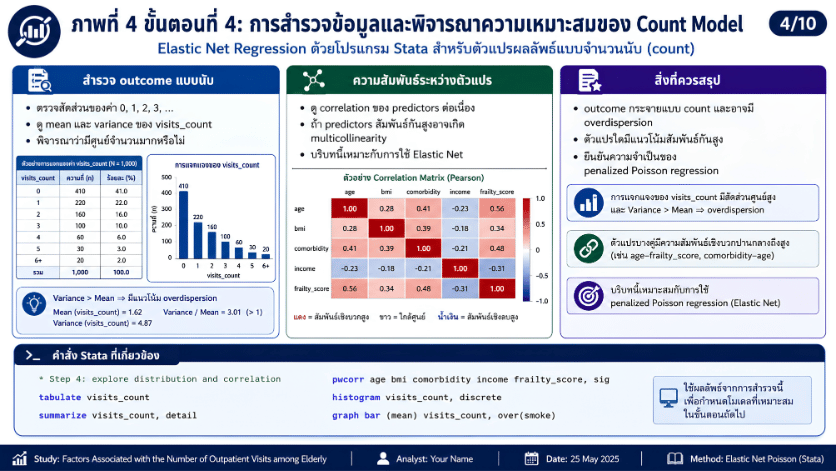
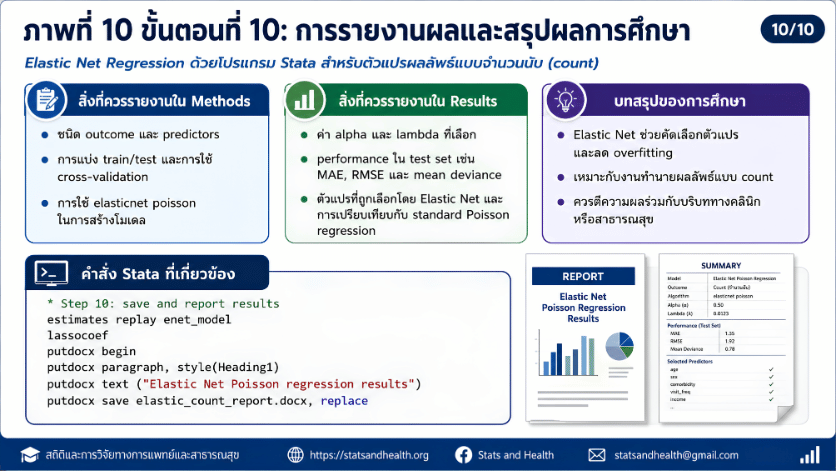
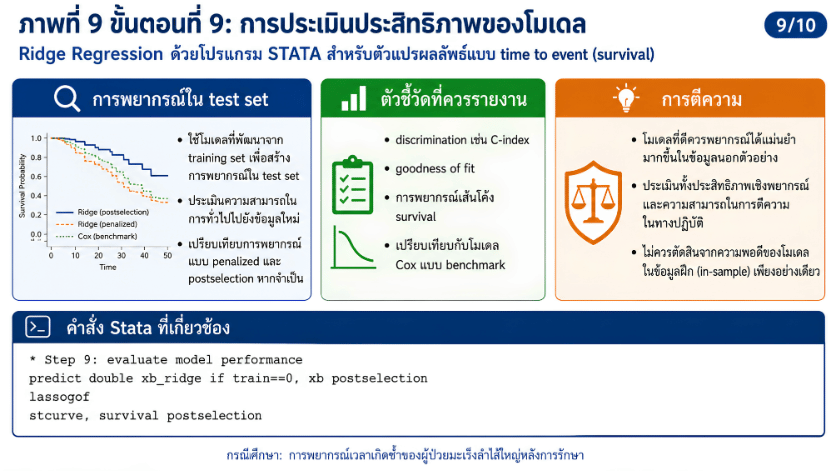
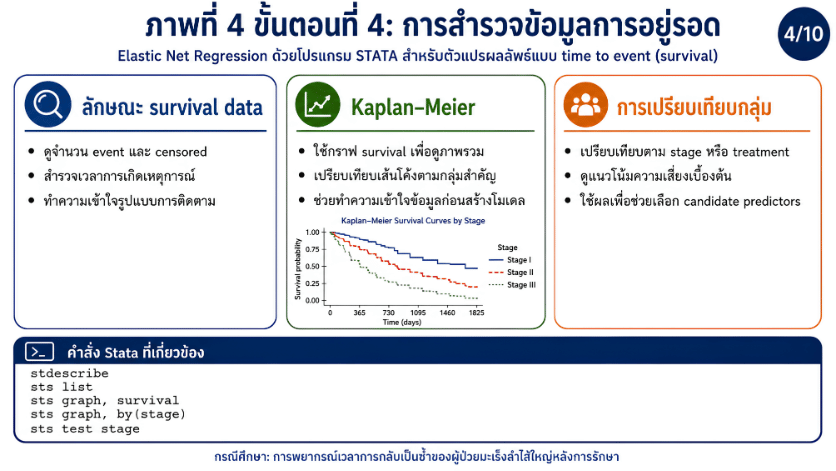
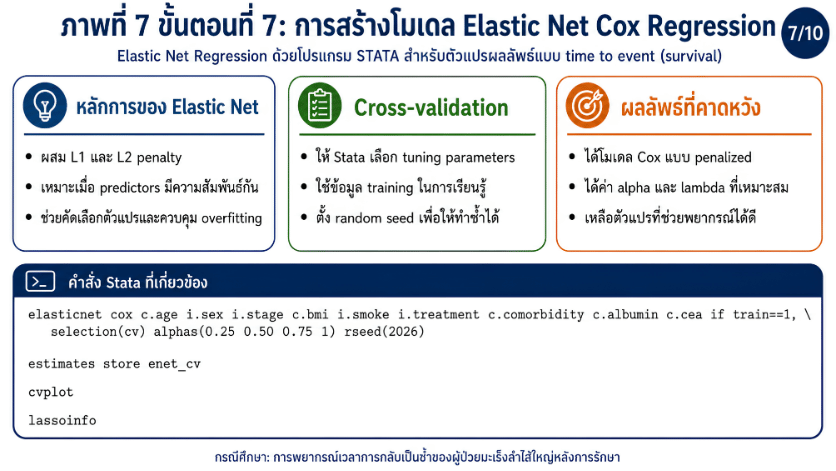
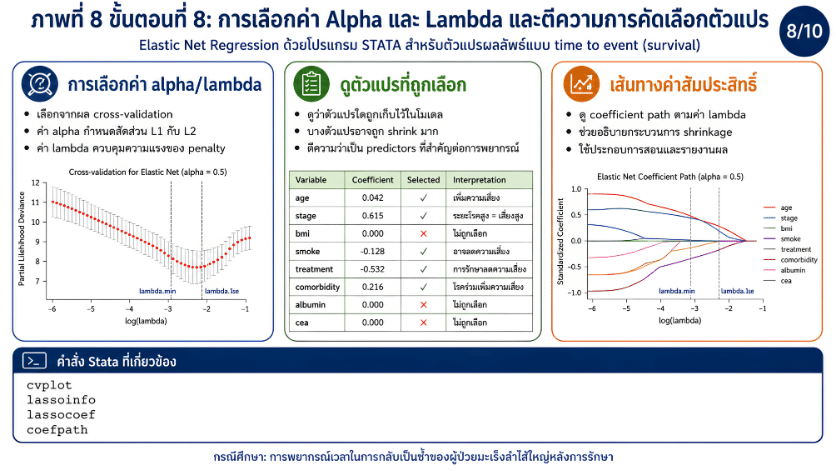
>>> ขั้นตอนการวิเคราะห์ Elastic Net Regression ด้วยโปรแกรม STATA
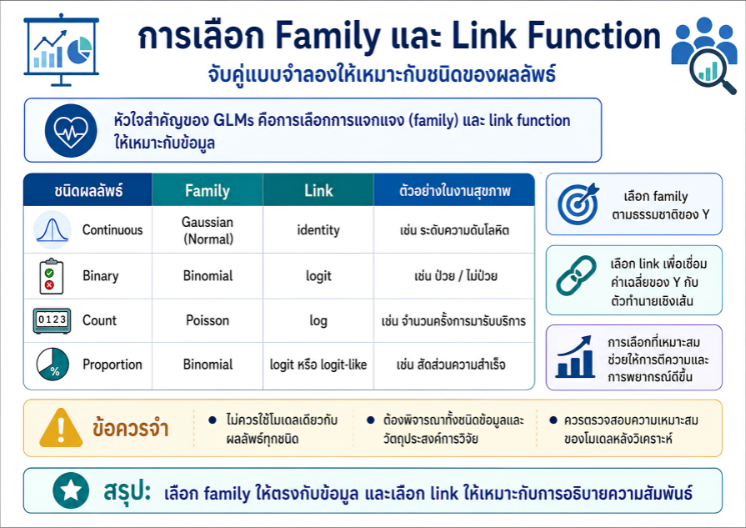
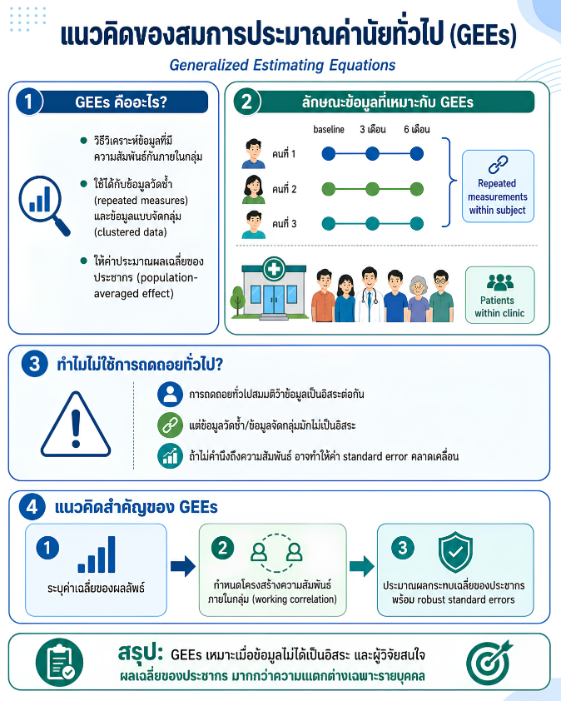
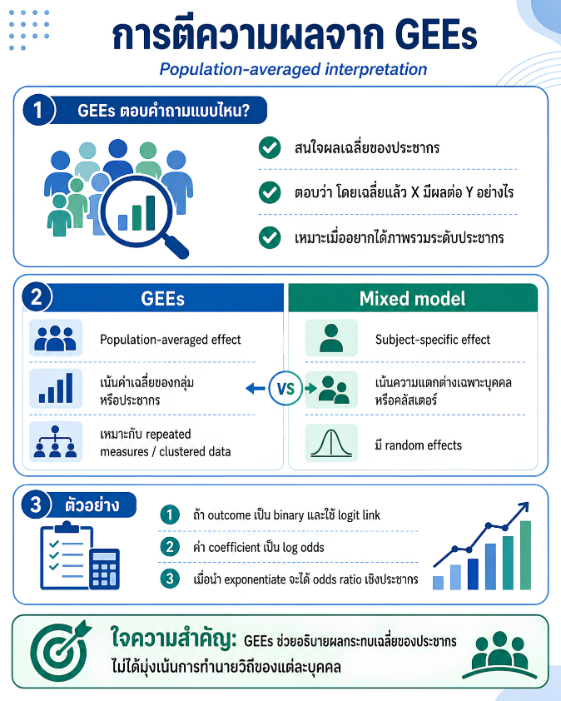
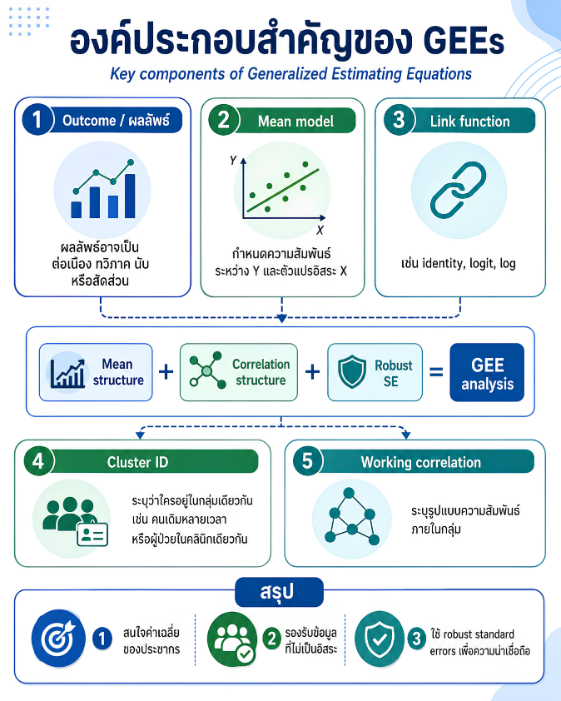
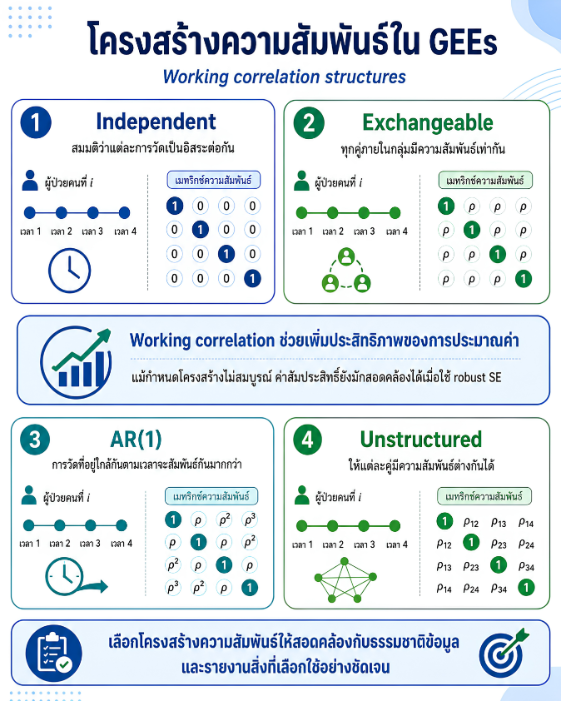
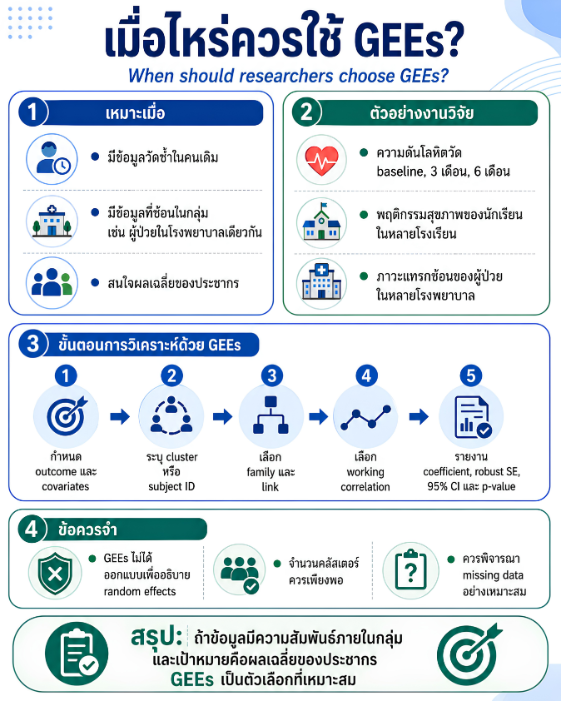
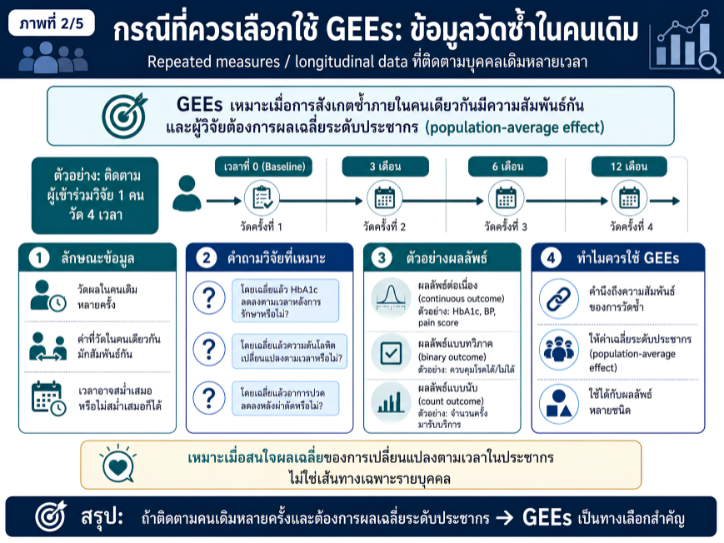
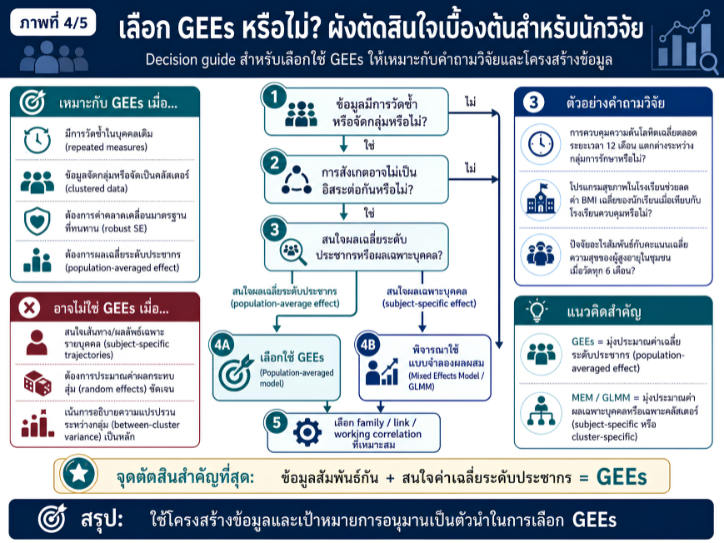
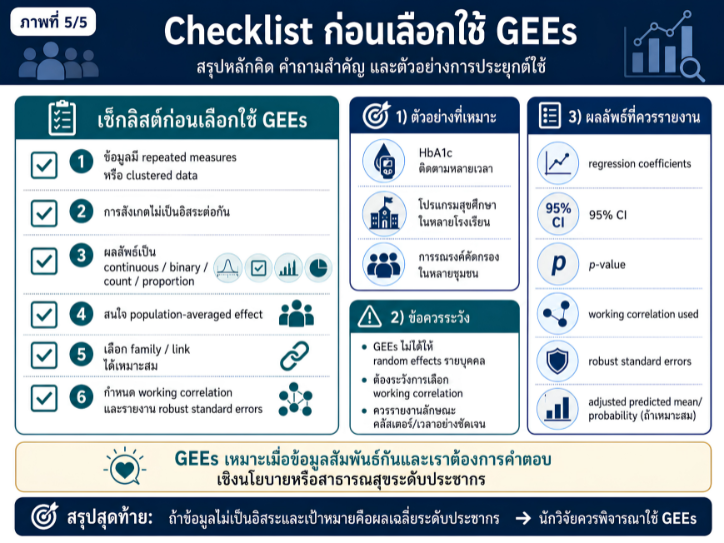
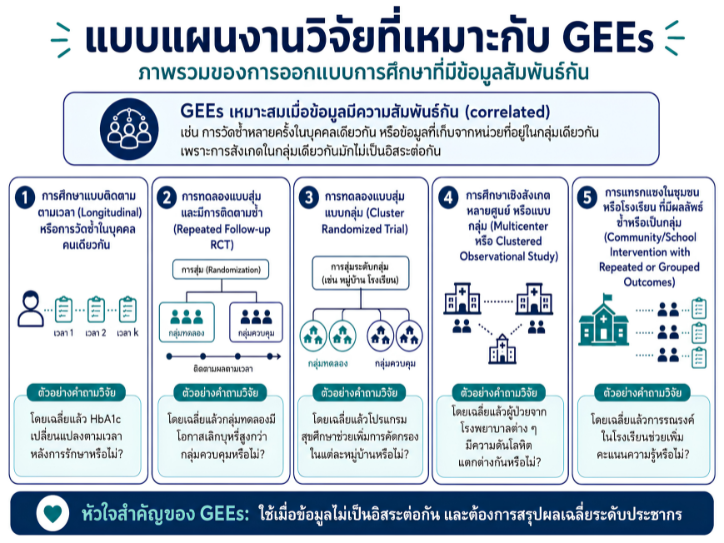
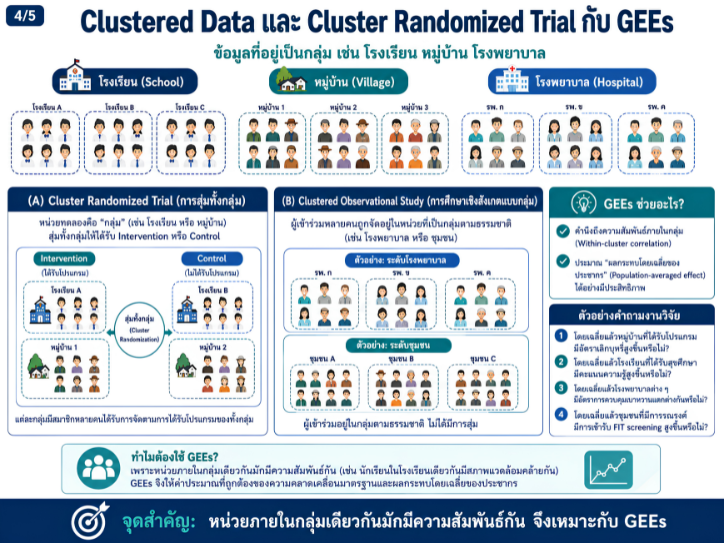
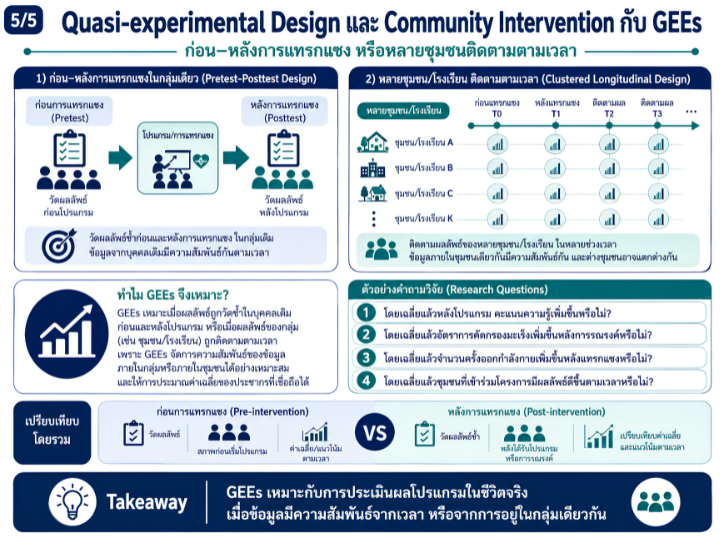
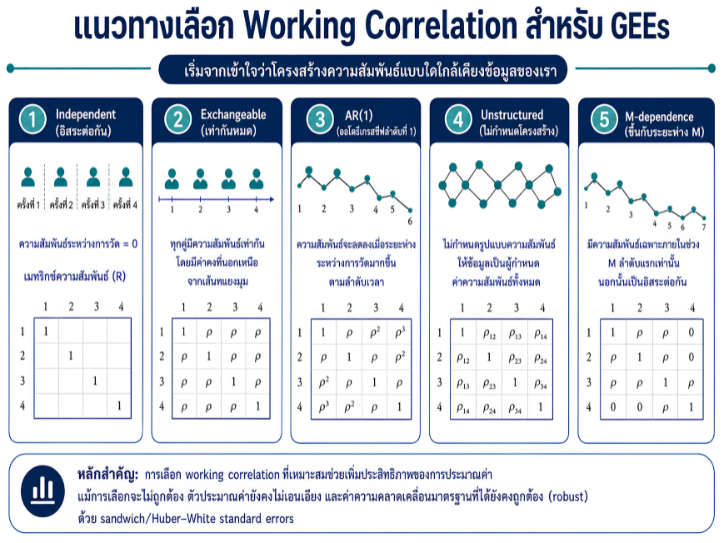
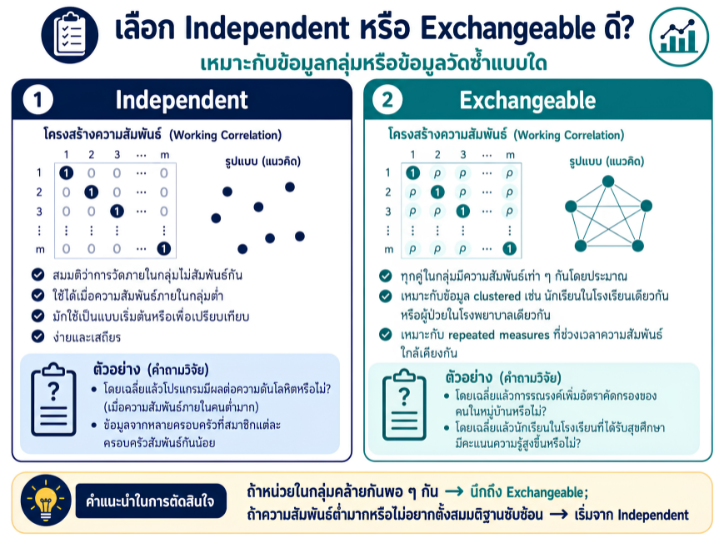
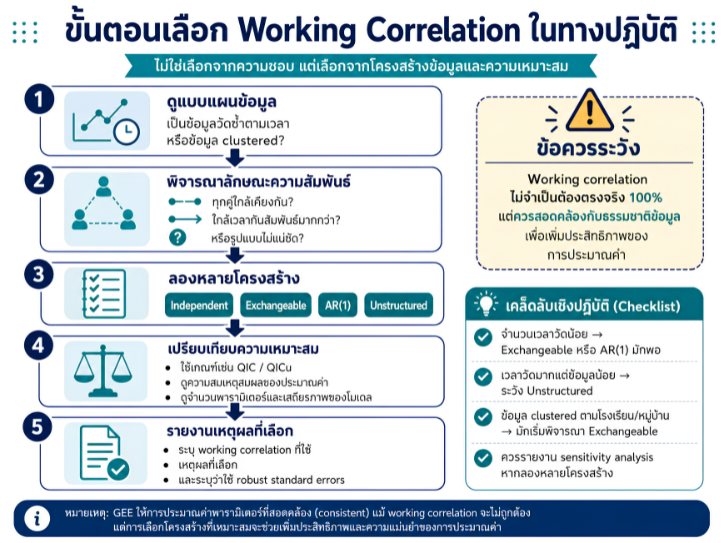
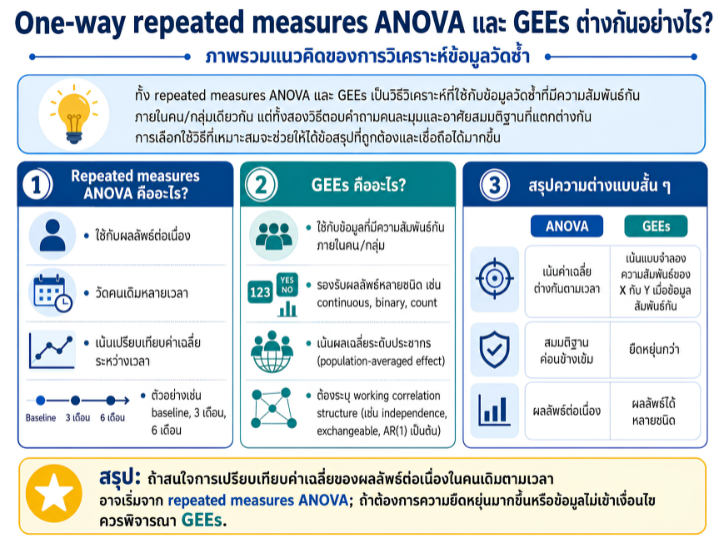
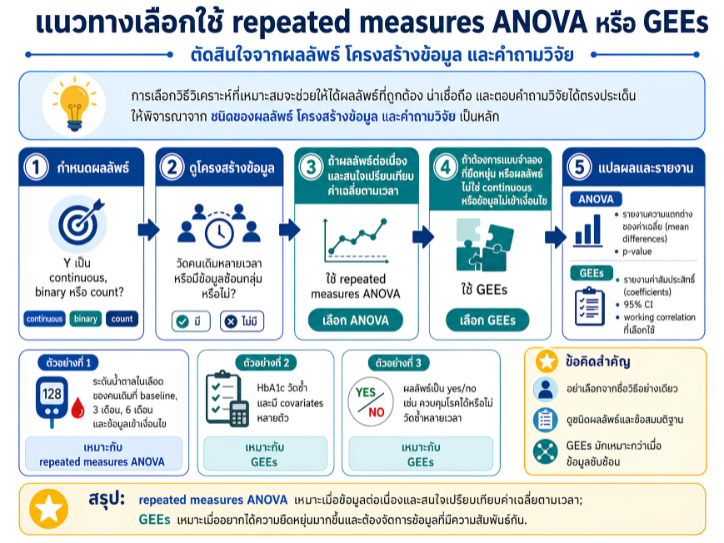
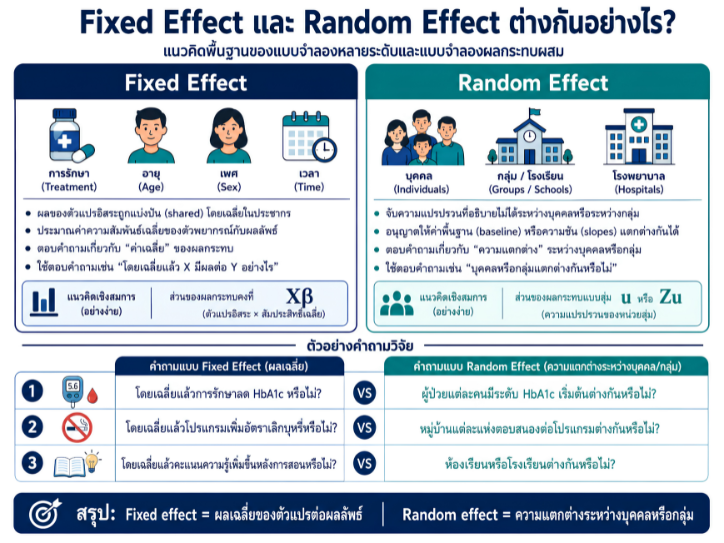
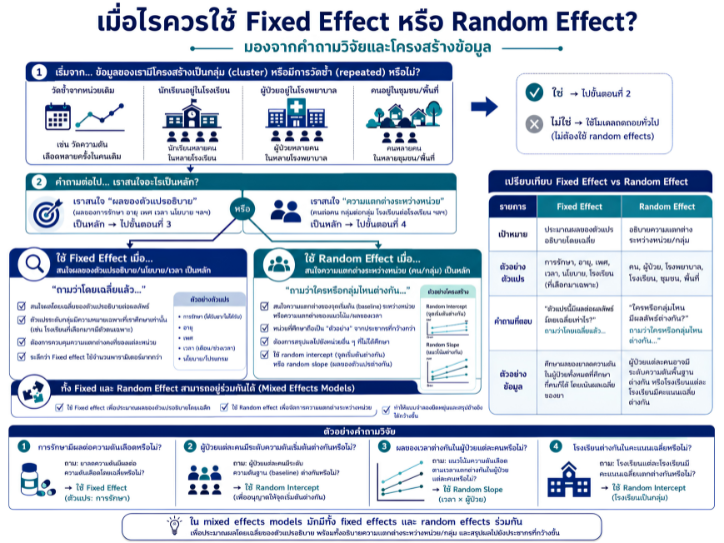
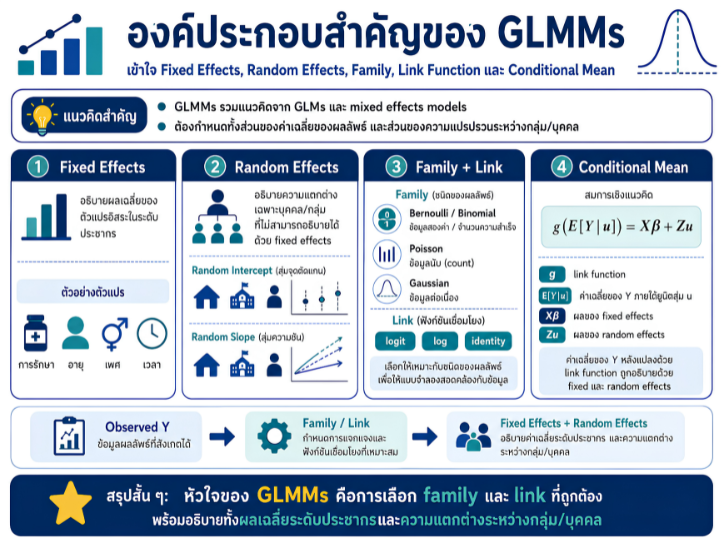
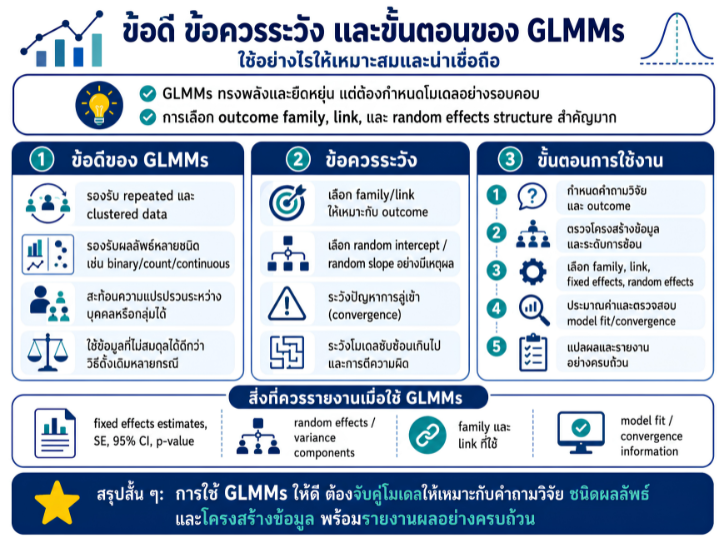
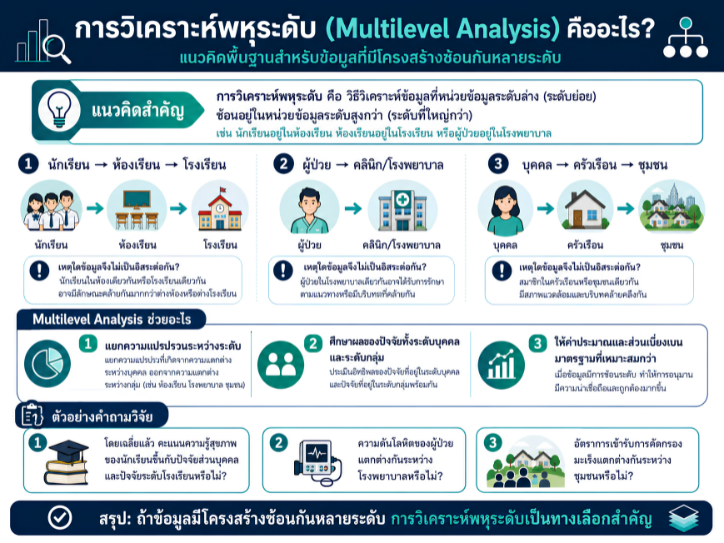
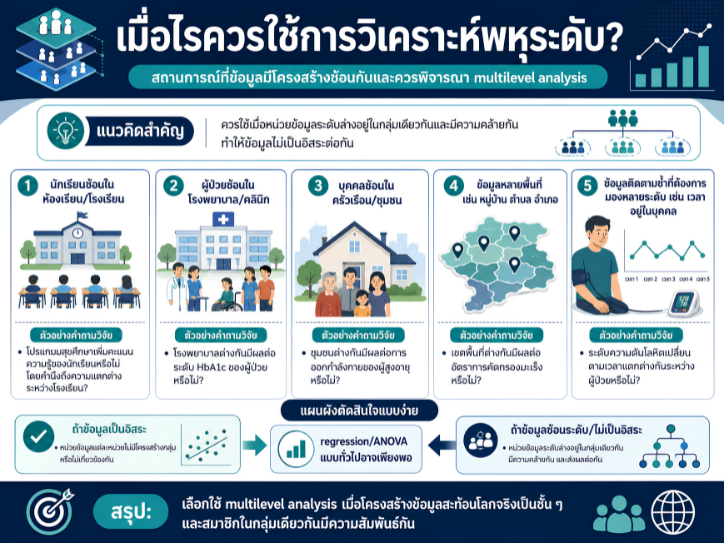
พื้นที่การเรียนรู้ชีวสถิติด้วยตนเองสำหรับงานวิจัยทางวิทยาศาสตร์สุขภาพ โดยเชื่อมโยงบทเรียนพื้นฐานกับบทความวิชาการต่อยอด เพื่อเตรียมความเข้าใจสู่การใช้ตัวแบบสถิติขั้นสูง ได้แก่ GLMs, GEEs, mixed effects models และ GLMMs
แหล่งรวบรวมบทความเกี่ยวกับเทคนิคการใช้ STATA ที่ต่อยอดจากพื้นฐาน โดยเน้นประเด็นที่นักวิจัยมักสับสน หรือ พบได้บ่อยในการวิเคราะห์ข้อมูลจริง เช่น การแปลผล regression การใช้ margins การจัดการข้อมูลวัดซ้ำ การใช้ GLMs/GEEs/mixed models และการจัดเตรียมผลลัพธ์สำหรับรายงานวิจัย หรือ ต้นฉบับบทความวิชาการ
แหล่งเรียนรู้สำหรับการทำความเข้าใจและประยุกต์ใช้ structural equation modeling และ generalized structural equation modeling ด้วยโปรแกรม STATA โดยเชื่อมโยงจาก regression, path analysis และ confirmatory factor analysis ไปสู่การวิเคราะห์ตัวแบบความสัมพันธ์เชิงโครงสร้างในงานวิจัยสุขภาพ ครอบคลุมทั้งข้อมูลต่อเนื่อง ข้อมูลทวิภาค ข้อมูลลำดับ และข้อมูลจำนวนนับ